민수가 선 그래프로 시계열 흐름을 완성하고 나서, 또 다른 요청을 꺼냈습니다.
"팀장님이 분기별로 카테고리 매출을 비교하는 차트도 원해. 의류, 식품, 전자기기, 도서 이렇게 네 가지 카테고리야."
지윤은 잠깐 생각했습니다. 카테고리 간 비교라면 막대 그래프가 딱이었습니다.
"막대 그래프로 가자. 그룹으로 할지 스택으로 할지는 보면서 결정하자."
px.bar() 기본
px.bar()는 x축에 카테고리, y축에 수치를 놓는 수직 막대 그래프를 기본으로 만듭니다.
# 파일: bar_basic.pyimport plotly.express as pximport pandas as pddf = pd.DataFrame({ "category": ["의류", "식품", "전자기기", "도서"], "sales": [3200, 4100, 5800, 1200]})fig = px.bar( df, x="category", y="sales", title="카테고리별 매출", labels={"category": "카테고리", "sales": "매출 (만원)"})fig.show()
수평 막대 그래프
카테고리 이름이 길거나 항목이 많을 때는 수평 막대 그래프가 읽기 편합니다. orientation='h'를 추가하고, x와 y 컬럼을 바꿉니다.
# 파일: bar_horizontal.pyimport plotly.express as pximport pandas as pddf = pd.DataFrame({ "category": ["의류", "식품", "전자기기", "도서"], "sales": [3200, 4100, 5800, 1200]})fig = px.bar( df, x="sales", y="category", orientation="h", title="카테고리별 매출 (수평)", labels={"category": "카테고리", "sales": "매출 (만원)"})fig.show()
그룹 막대 그래프
분기별 카테고리를 한 차트에 나타내려면 color로 그룹을 나누고 barmode='group'을 지정합니다.
# 파일: bar_group.pyimport plotly.express as pximport pandas as pddf = pd.DataFrame({ "quarter": ["Q1", "Q1", "Q1", "Q1", "Q2", "Q2", "Q2", "Q2", "Q3", "Q3", "Q3", "Q3", "Q4", "Q4", "Q4", "Q4"], "category": ["의류", "식품", "전자기기", "도서"] * 4, "sales": [ 3200, 4100, 5800, 1200, # Q1 2900, 4500, 6200, 1100, # Q2 4100, 3800, 5500, 1400, # Q3 5800, 4200, 7100, 1800 # Q4 ]})fig = px.bar( df, x="quarter", y="sales", color="category", barmode="group", title="분기별 카테고리 매출 비교 (그룹)", labels={"quarter": "분기", "sales": "매출 (만원)", "category": "카테고리"})fig.show()
같은 분기 내에서 카테고리별 막대가 나란히 배치됩니다. 절대적인 크기 비교에 유리합니다.
스택 막대 그래프
각 카테고리가 분기 전체 매출에서 차지하는 비중을 보고 싶다면 스택 막대 그래프가 적합합니다. barmode='stack'으로 변경합니다.
# 파일: bar_stack.pyimport plotly.express as pximport pandas as pddf = pd.DataFrame({ "quarter": ["Q1", "Q1", "Q1", "Q1", "Q2", "Q2", "Q2", "Q2", "Q3", "Q3", "Q3", "Q3", "Q4", "Q4", "Q4", "Q4"], "category": ["의류", "식품", "전자기기", "도서"] * 4, "sales": [ 3200, 4100, 5800, 1200, 2900, 4500, 6200, 1100, 4100, 3800, 5500, 1400, 5800, 4200, 7100, 1800 ]})fig = px.bar( df, x="quarter", y="sales", color="category", barmode="stack", title="분기별 카테고리 매출 비교 (스택)", labels={"quarter": "분기", "sales": "매출 (만원)", "category": "카테고리"})fig.show()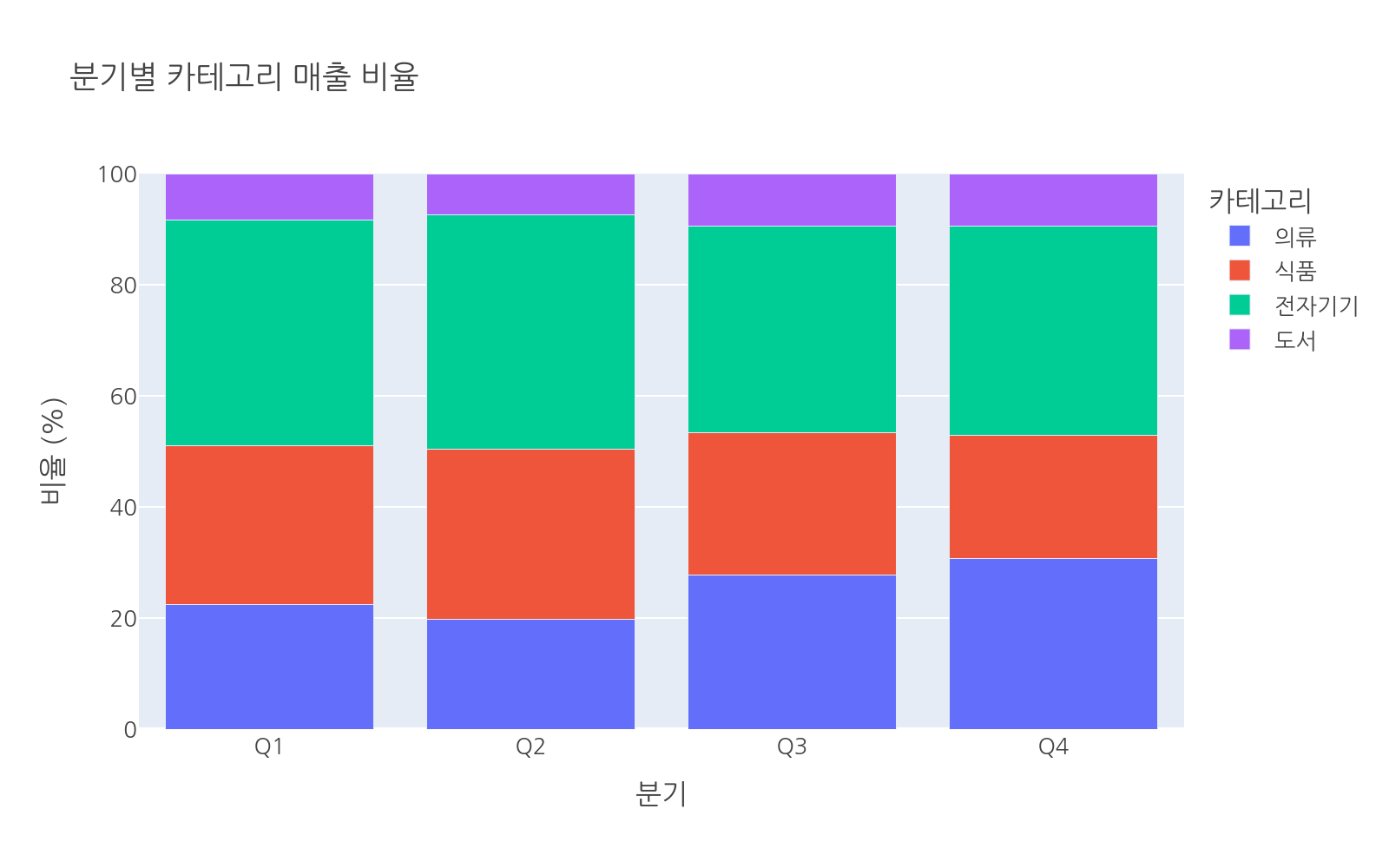
각 분기의 전체 매출 높이와 카테고리 구성 비율을 동시에 파악할 수 있습니다.
상대 스택 (비율)
절대 수치 대신 비율로 표현하고 싶다면 barmode='relative'로 설정하고, 각 값이 100%를 채우도록 Plotly가 자동 계산합니다. 단, y 값이 음수인 경우에도 쓸 수 있는 방식입니다.
비율 히스토그램처럼 모든 막대를 100%로 맞추려면 barnorm='percent'를 사용합니다.
# 파일: bar_percent.pyimport plotly.express as pximport pandas as pddf = pd.DataFrame({ "quarter": ["Q1", "Q1", "Q1", "Q1", "Q2", "Q2", "Q2", "Q2", "Q3", "Q3", "Q3", "Q3", "Q4", "Q4", "Q4", "Q4"], "category": ["의류", "식품", "전자기기", "도서"] * 4, "sales": [ 3200, 4100, 5800, 1200, 2900, 4500, 6200, 1100, 4100, 3800, 5500, 1400, 5800, 4200, 7100, 1800 ]})fig = px.bar( df, x="quarter", y="sales", color="category", barmode="stack", title="분기별 카테고리 매출 비율", labels={"quarter": "분기", "sales": "비율 (%)", "category": "카테고리"})fig.update_layout(barnorm="percent")fig.show()text_auto로 값 표시
막대 위에 수치를 직접 표시하면 호버하지 않아도 값을 바로 읽을 수 있습니다. text_auto=True를 추가합니다.
# 파일: bar_text.pyimport plotly.express as pximport pandas as pddf = pd.DataFrame({ "category": ["의류", "식품", "전자기기", "도서"], "sales": [3200, 4100, 5800, 1200]})fig = px.bar( df, x="category", y="sales", text_auto=True, title="카테고리별 매출", labels={"category": "카테고리", "sales": "매출 (만원)"})fig.update_traces(textposition="outside") # 막대 바깥쪽에 표시fig.show()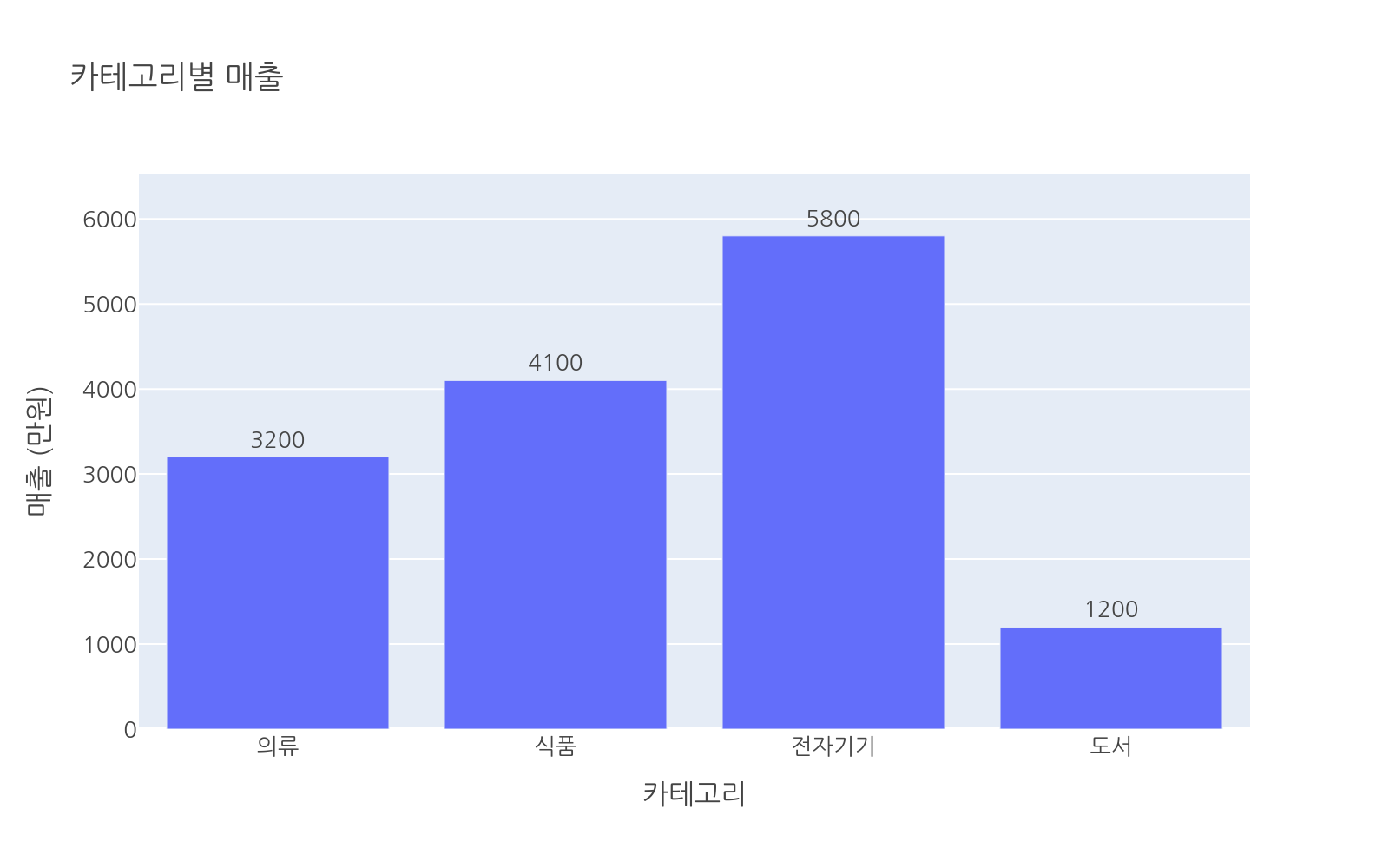
textposition 옵션으로 텍스트 위치를 조정합니다.
| 값 | 설명 |
|---|---|
"outside" |
막대 바깥 (기본) |
"inside" |
막대 안쪽 |
"auto" |
공간에 따라 자동 |
barmode 정리
| barmode | 용도 |
|---|---|
"group" |
그룹 내 카테고리 절대값 비교 |
"stack" |
전체 합계와 구성 비율 동시 파악 |
"relative" |
양수/음수 값이 섞인 데이터 |
barnorm="percent" |
비율(100%) 기반 비교 |
민수가 네 가지 barmode를 모두 실행해보더니 말했습니다.
"발표할 때는 그룹이 낫겠다. 분기별 전자기기 증가가 눈에 바로 들어와."
지윤도 동의했습니다. 어떤 메시지를 전달하느냐에 따라 같은 데이터도 다르게 보였습니다.