"시험 점수 분포부터 보자."
준호가 말했습니다. 지윤은 히스토그램을 떠올렸습니다. 분포를 볼 때 가장 기본이 되는 차트였습니다. 데이터가 어떤 구간에 몰려 있는지 한눈에 파악할 수 있었습니다.
px.histogram() 기본
px.histogram()은 수치형 컬럼 하나를 받아 자동으로 구간을 나누고 빈도를 계산합니다. 데이터프레임의 컬럼명을 x에 지정합니다.
# 파일: histogram_basic.pyimport plotly.express as pximport numpy as npimport pandas as pdnp.random.seed(42)scores = np.random.normal(loc=72, scale=12, size=200).clip(0, 100)df = pd.DataFrame({"score": scores})fig = px.histogram( df, x="score", title="중간고사 점수 분포", labels={"score": "점수", "count": "학생 수"})fig.show()
Plotly가 자동으로 구간을 나눕니다. 각 막대에 마우스를 올리면 구간과 빈도가 표시됩니다.
nbins로 구간 수 조절
자동으로 결정된 구간이 너무 많거나 적을 때 nbins 파라미터로 직접 지정합니다.
# 파일: histogram_nbins.pyimport plotly.express as pximport numpy as npimport pandas as pdnp.random.seed(42)scores = np.random.normal(loc=72, scale=12, size=200).clip(0, 100)df = pd.DataFrame({"score": scores})fig = px.histogram( df, x="score", nbins=20, title="중간고사 점수 분포 (20구간)", labels={"score": "점수"})fig.show()
구간이 많을수록 세밀한 분포를 보여주지만 데이터가 적으면 들쭉날쭉해집니다. 데이터 수에 맞게 조정합니다.
그룹 히스토그램
color 파라미터로 여러 그룹의 분포를 하나의 차트에 겹쳐서 볼 수 있습니다.
# 파일: histogram_group.pyimport plotly.express as pximport numpy as npimport pandas as pdnp.random.seed(42)n = 150df = pd.DataFrame({ "score": np.concatenate([ np.random.normal(68, 10, n).clip(0, 100), # 통계학과 np.random.normal(75, 9, n).clip(0, 100) # 컴퓨터공학과 ]), "major": ["통계학과"] * n + ["컴퓨터공학과"] * n})fig = px.histogram( df, x="score", color="major", barmode="overlay", nbins=25, title="학과별 점수 분포 비교", labels={"score": "점수", "major": "학과"})fig.update_traces(opacity=0.7)fig.show()
barmode="overlay"로 두 히스토그램을 겹칩니다. opacity=0.7로 투명도를 조정해야 뒤에 있는 막대도 보입니다.
marginal로 보조 분포 추가
marginal 파라미터를 사용하면 히스토그램 위에 분포를 요약하는 보조 차트가 추가됩니다.
# 파일: histogram_marginal.pyimport plotly.express as pximport numpy as npimport pandas as pdnp.random.seed(42)scores = np.random.normal(loc=72, scale=12, size=200).clip(0, 100)df = pd.DataFrame({"score": scores})fig = px.histogram( df, x="score", nbins=20, marginal="box", title="중간고사 점수 분포 (박스플롯 주변 분포 포함)", labels={"score": "점수"})fig.show()
히스토그램 위에 박스플롯이 추가됩니다. marginal에 사용할 수 있는 값은 다음과 같습니다.
| 값 | 설명 |
|---|---|
"box" |
박스플롯 |
"violin" |
바이올린 플롯 |
"rug" |
개별 데이터 점 표시 (러그 플롯) |
histnorm으로 비율 히스토그램
빈도 대신 비율(퍼센트)로 표현하고 싶을 때 histnorm="percent"를 사용합니다. 두 그룹의 데이터 수가 다를 때 공정하게 비교할 수 있습니다.
# 파일: histogram_percent.pyimport plotly.express as pximport numpy as npimport pandas as pdnp.random.seed(42)df = pd.DataFrame({ "score": np.concatenate([ np.random.normal(68, 10, 150).clip(0, 100), np.random.normal(75, 9, 100).clip(0, 100) # 데이터 수 다름 ]), "major": ["통계학과"] * 150 + ["컴퓨터공학과"] * 100})fig = px.histogram( df, x="score", color="major", barmode="overlay", nbins=20, histnorm="percent", title="학과별 점수 비율 분포", labels={"score": "점수", "major": "학과"})fig.update_traces(opacity=0.7)fig.show()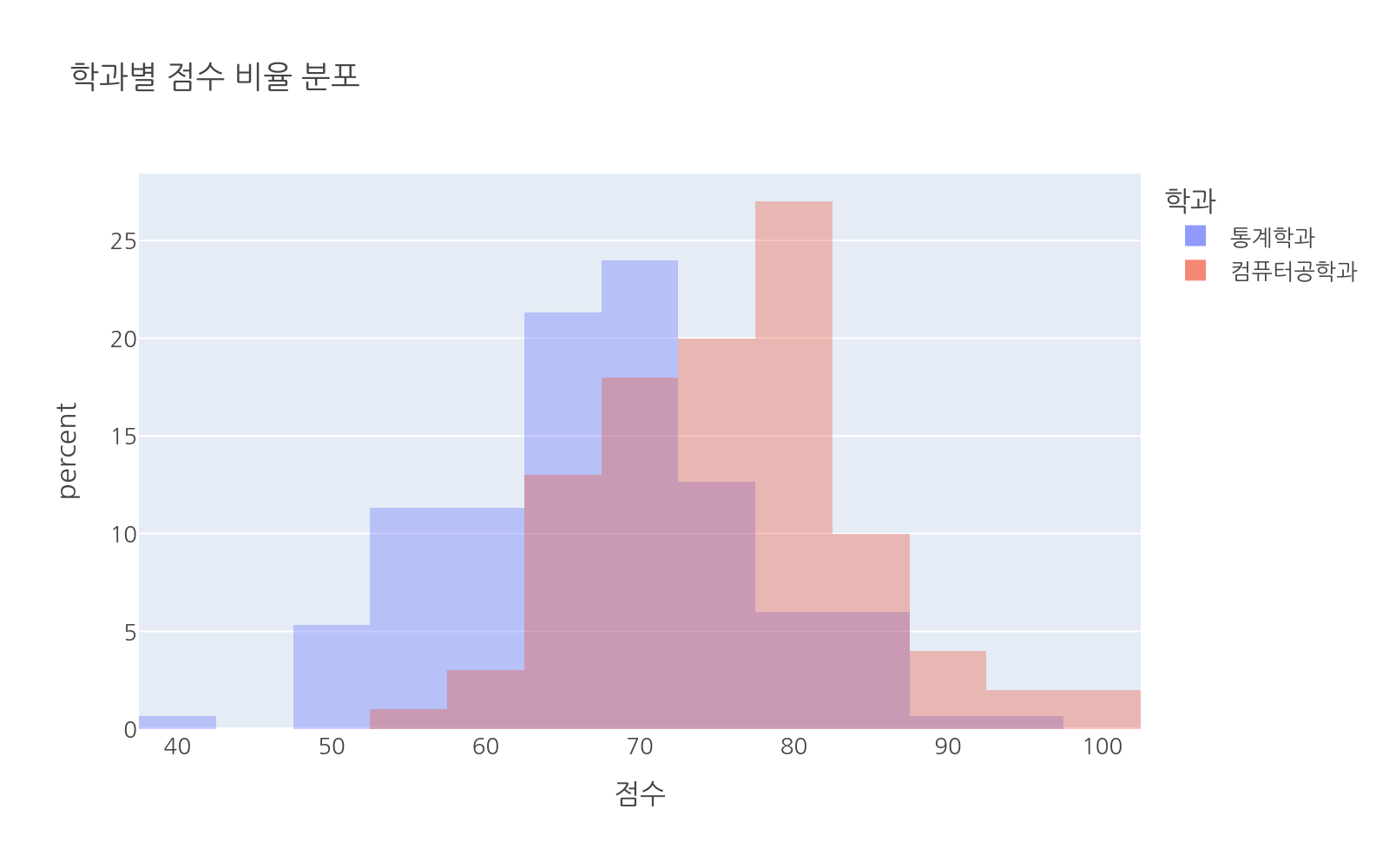
histnorm에 사용할 수 있는 값은 다음과 같습니다.
| 값 | y축 의미 |
|---|---|
| 기본(없음) | 빈도(count) |
"percent" |
전체 대비 퍼센트 |
"probability" |
전체 대비 확률 (0~1) |
"density" |
밀도 |
"probability density" |
확률 밀도 |
실전: 준호의 시험 점수 분포
준호가 최종 버전을 요청했습니다. 중간고사와 기말고사를 나란히 비교하고 싶다고 했습니다.
# 파일: exam_histogram.pyimport plotly.express as pximport numpy as npimport pandas as pdnp.random.seed(0)n = 180df = pd.DataFrame({ "score": np.concatenate([ np.random.normal(70, 13, n).clip(0, 100), np.random.normal(76, 11, n).clip(0, 100) ]), "exam": ["중간고사"] * n + ["기말고사"] * n})fig = px.histogram( df, x="score", color="exam", barmode="overlay", nbins=20, histnorm="percent", marginal="box", title="중간고사 vs 기말고사 점수 분포", labels={"score": "점수 (%)", "exam": "시험", "percent": "비율 (%)"})fig.update_traces(opacity=0.65)fig.update_layout( xaxis_title="점수", yaxis_title="비율 (%)")fig.show()
준호가 화면을 보고 말했습니다.
"기말이 중간보다 전체적으로 높네. 공부를 더 많이 한 거겠지."
위에 있는 박스플롯도 같은 이야기를 하고 있었습니다. 기말고사 박스플롯의 중앙값이 더 오른쪽에 있었습니다.