히스토그램으로 전체 분포를 파악했습니다. 이제 준호가 다음 데이터를 꺼냈습니다.
"학과별 성적 분포도 비교해야 해. 다섯 개 학과야. 히스토그램으로 다섯 개 겹치면 너무 복잡할 것 같아서."
지윤이 고개를 끄덕였습니다.
"그럴 때 박스플롯이 나와. 히스토그램보다 정보를 압축해서 보여주거든."
px.box() 기본
px.box()는 최솟값, 1사분위수(Q1), 중앙값(Q2), 3사분위수(Q3), 최댓값을 박스와 선으로 표현합니다.
# 파일: box_basic.pyimport plotly.express as pximport numpy as npimport pandas as pdnp.random.seed(1)majors = ["통계학과", "컴퓨터공학과", "수학과", "경영학과", "물리학과"]n_per = 80data = []means = [72, 78, 74, 70, 76]stds = [10, 9, 11, 12, 8]for major, mean, std in zip(majors, means, stds): scores = np.random.normal(mean, std, n_per).clip(0, 100) for s in scores: data.append({"major": major, "score": s})df = pd.DataFrame(data)fig = px.box( df, x="major", y="score", title="학과별 성적 분포", labels={"major": "학과", "score": "점수"})fig.show()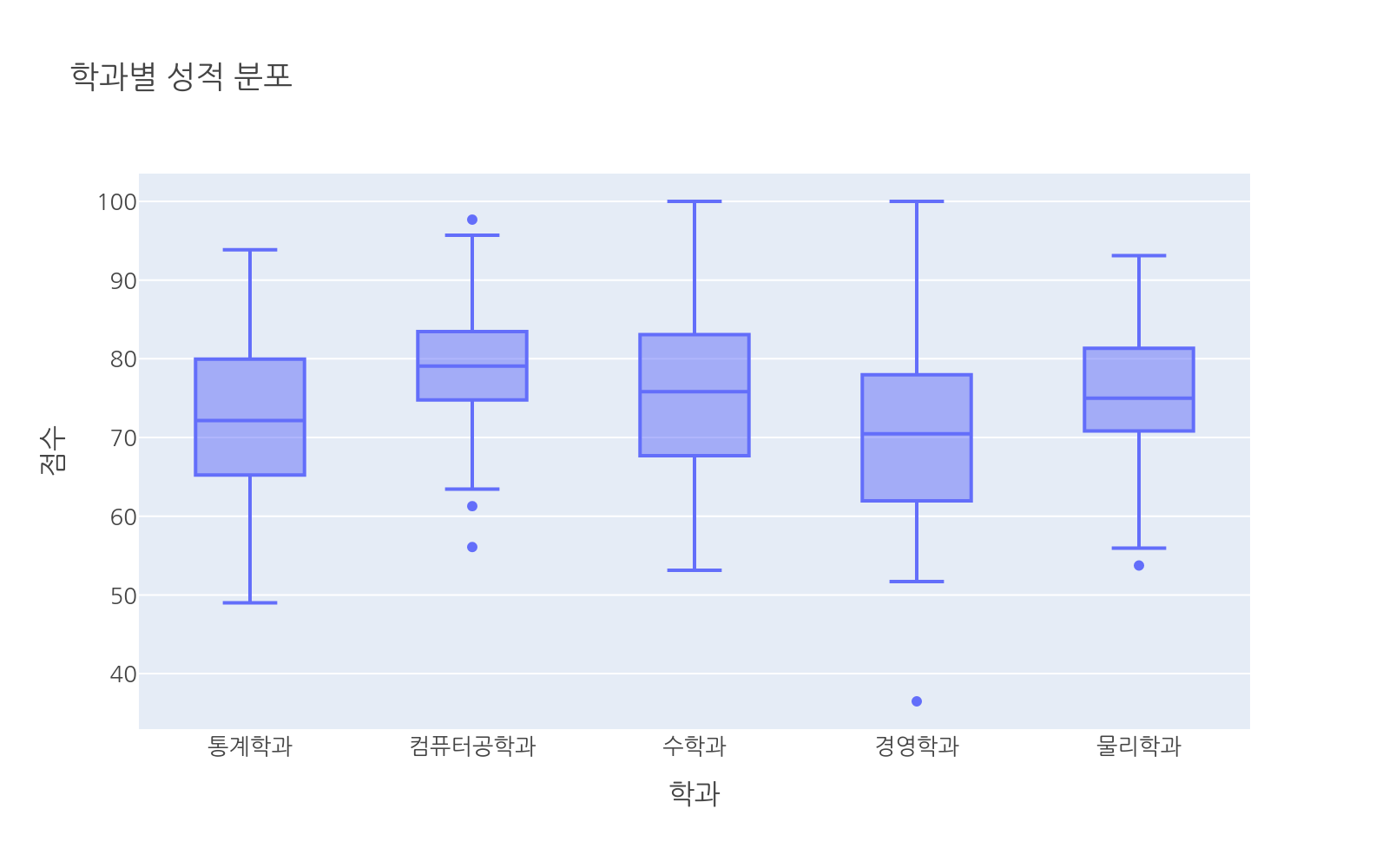
박스의 아래 선이 Q1, 가운데 선이 중앙값, 위 선이 Q3입니다. 박스 위아래로 뻗은 수염은 이상치를 제외한 최소, 최대 범위를 나타냅니다.
박스플롯 읽는 법
박스플롯이 처음이라면 구성 요소를 한 번 정리해두는 것이 좋습니다.
| ← 최댓값 (이상치 제외)
┌──┴──┐
│ │ ← Q3 (75번째 백분위)
│─────│ ← 중앙값 (50번째 백분위)
│ │ ← Q1 (25번째 백분위)
└──┬──┘
| ← 최솟값 (이상치 제외)
○ ← 이상치 (IQR × 1.5 초과)
IQR(사분위 범위) = Q3 - Q1이며, Q3 + 1.5×IQR을 초과하거나 Q1 - 1.5×IQR 미만인 점은 이상치로 표시됩니다.
color로 그룹 구분
color 파라미터를 추가하면 박스별로 색상이 자동으로 배정됩니다.
# 파일: box_color.pyimport plotly.express as pximport numpy as npimport pandas as pdnp.random.seed(1)majors = ["통계학과", "컴퓨터공학과", "수학과", "경영학과", "물리학과"]n_per = 80means = [72, 78, 74, 70, 76]stds = [10, 9, 11, 12, 8]data = []for major, mean, std in zip(majors, means, stds): for s in np.random.normal(mean, std, n_per).clip(0, 100): data.append({"major": major, "score": s})df = pd.DataFrame(data)fig = px.box( df, x="major", y="score", color="major", title="학과별 성적 분포", labels={"major": "학과", "score": "점수"})fig.show()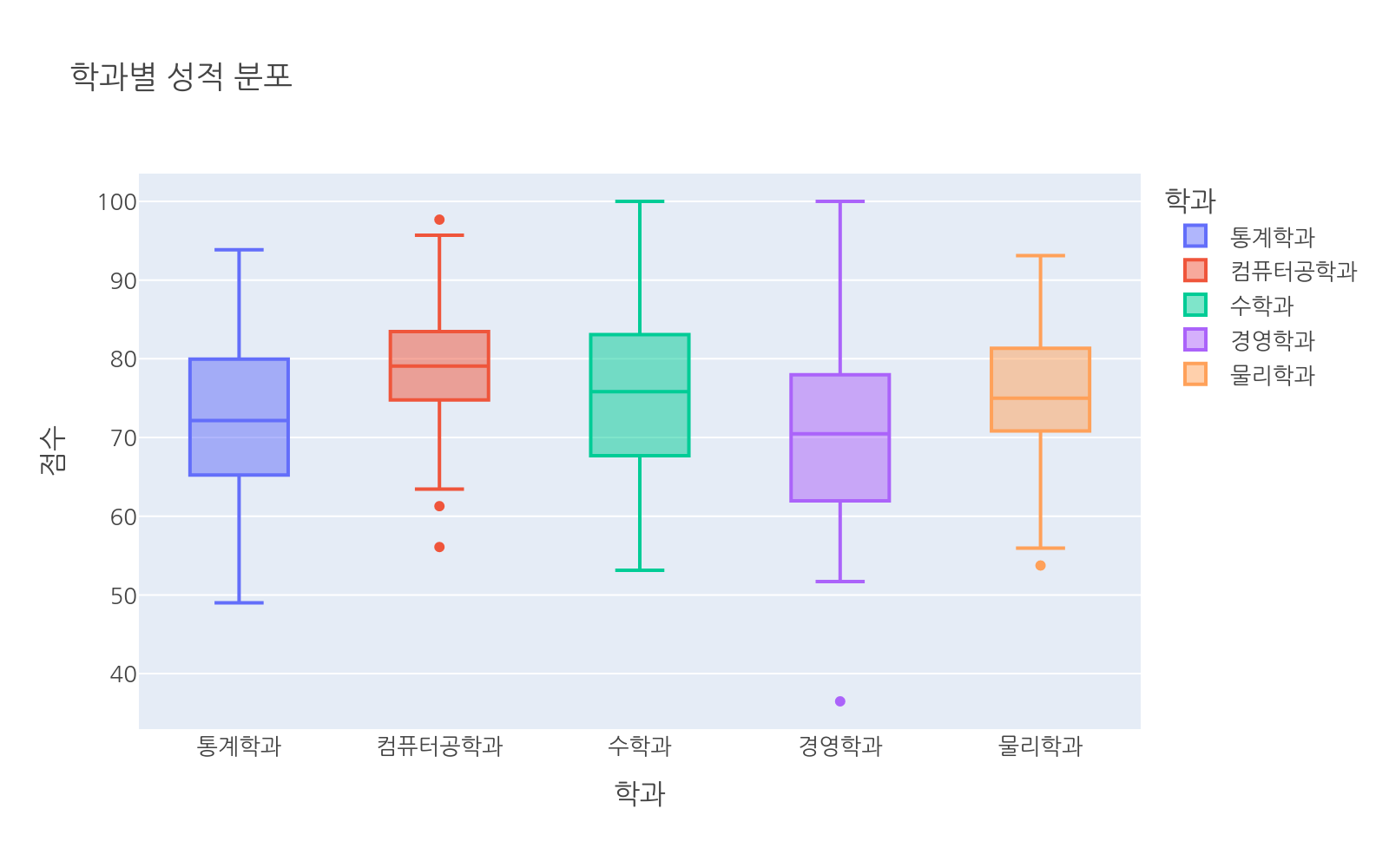
points로 개별 데이터 표시
박스플롯은 요약 통계를 보여주지만 개별 데이터 점이 어디 있는지는 숨깁니다. points 파라미터로 점을 추가할 수 있습니다.
# 파일: box_points.pyimport plotly.express as pximport numpy as npimport pandas as pdnp.random.seed(1)data = []for major, mean, std in zip( ["통계학과", "컴퓨터공학과", "수학과"], [72, 78, 74], [10, 9, 11]): for s in np.random.normal(mean, std, 50).clip(0, 100): data.append({"major": major, "score": s})df = pd.DataFrame(data)fig = px.box( df, x="major", y="score", color="major", points="all", title="학과별 성적 분포 (개별 데이터 포함)", labels={"major": "학과", "score": "점수"})fig.show()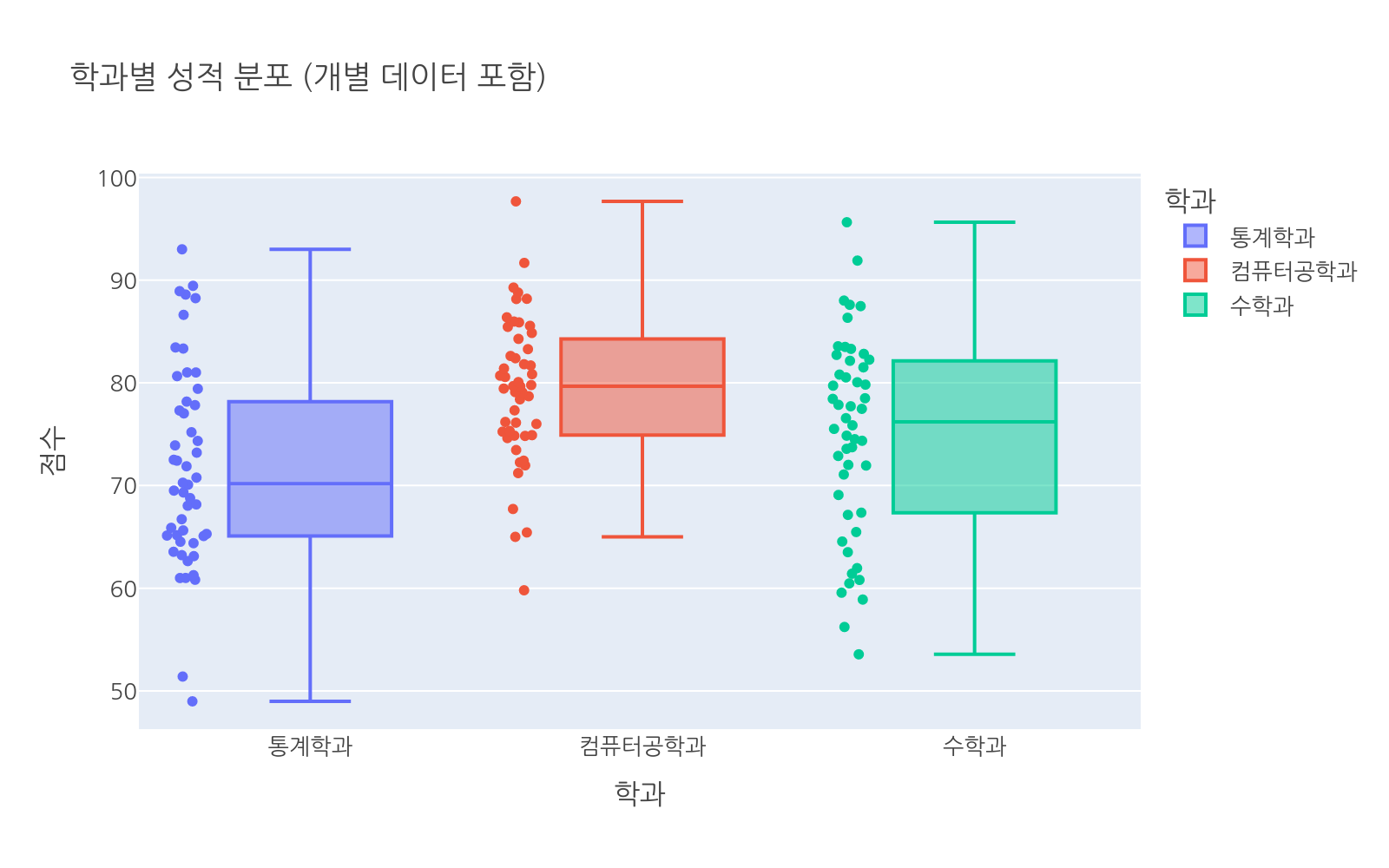
points 값 |
설명 |
|---|---|
False |
점 없음 |
"outliers" |
이상치만 표시 (기본) |
"suspected outliers" |
이상치 + 경계 근처 |
"all" |
모든 데이터 점 표시 |
px.violin() 기본
바이올린 플롯은 박스플롯에 밀도 분포 정보를 더한 차트입니다. 박스는 분포의 경계만 보여주지만 바이올린은 어느 구간에 데이터가 몰려 있는지까지 시각화합니다.
# 파일: violin_basic.pyimport plotly.express as pximport numpy as npimport pandas as pdnp.random.seed(1)majors = ["통계학과", "컴퓨터공학과", "수학과", "경영학과", "물리학과"]n_per = 80means = [72, 78, 74, 70, 76]stds = [10, 9, 11, 12, 8]data = []for major, mean, std in zip(majors, means, stds): for s in np.random.normal(mean, std, n_per).clip(0, 100): data.append({"major": major, "score": s})df = pd.DataFrame(data)fig = px.violin( df, x="major", y="score", color="major", box=True, # 내부에 박스플롯도 표시 points="outliers", title="학과별 성적 분포 (바이올린)", labels={"major": "학과", "score": "점수"})fig.show()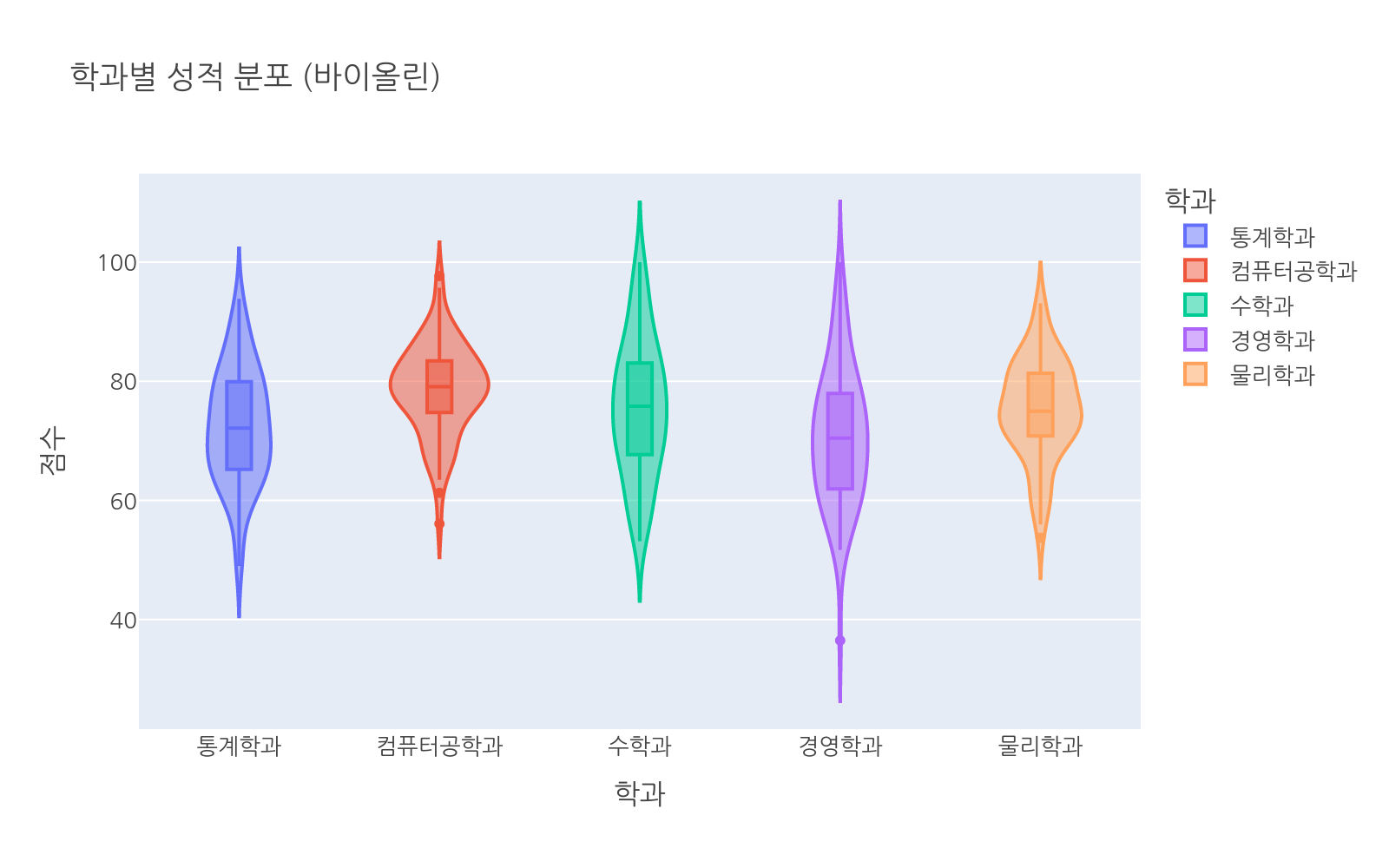
box=True를 추가하면 바이올린 안에 박스플롯이 함께 표시됩니다.
violinmode로 양쪽 바이올린
두 그룹을 같은 x 위치에서 좌우로 나눠 비교할 수 있습니다. violinmode="overlay"는 겹치고, "group"은 나란히 배치합니다.
# 파일: violin_split.pyimport plotly.express as pximport numpy as npimport pandas as pdnp.random.seed(5)majors = ["통계학과", "컴퓨터공학과", "수학과"]n = 60data = []for major, mean_m, mean_f in zip( majors, [74, 79, 72], [70, 76, 75]): for s in np.random.normal(mean_m, 10, n).clip(0, 100): data.append({"major": major, "score": s, "gender": "남"}) for s in np.random.normal(mean_f, 10, n).clip(0, 100): data.append({"major": major, "score": s, "gender": "여"})df = pd.DataFrame(data)fig = px.violin( df, x="major", y="score", color="gender", violinmode="group", box=True, title="학과 및 성별 성적 분포", labels={"major": "학과", "score": "점수", "gender": "성별"})fig.show()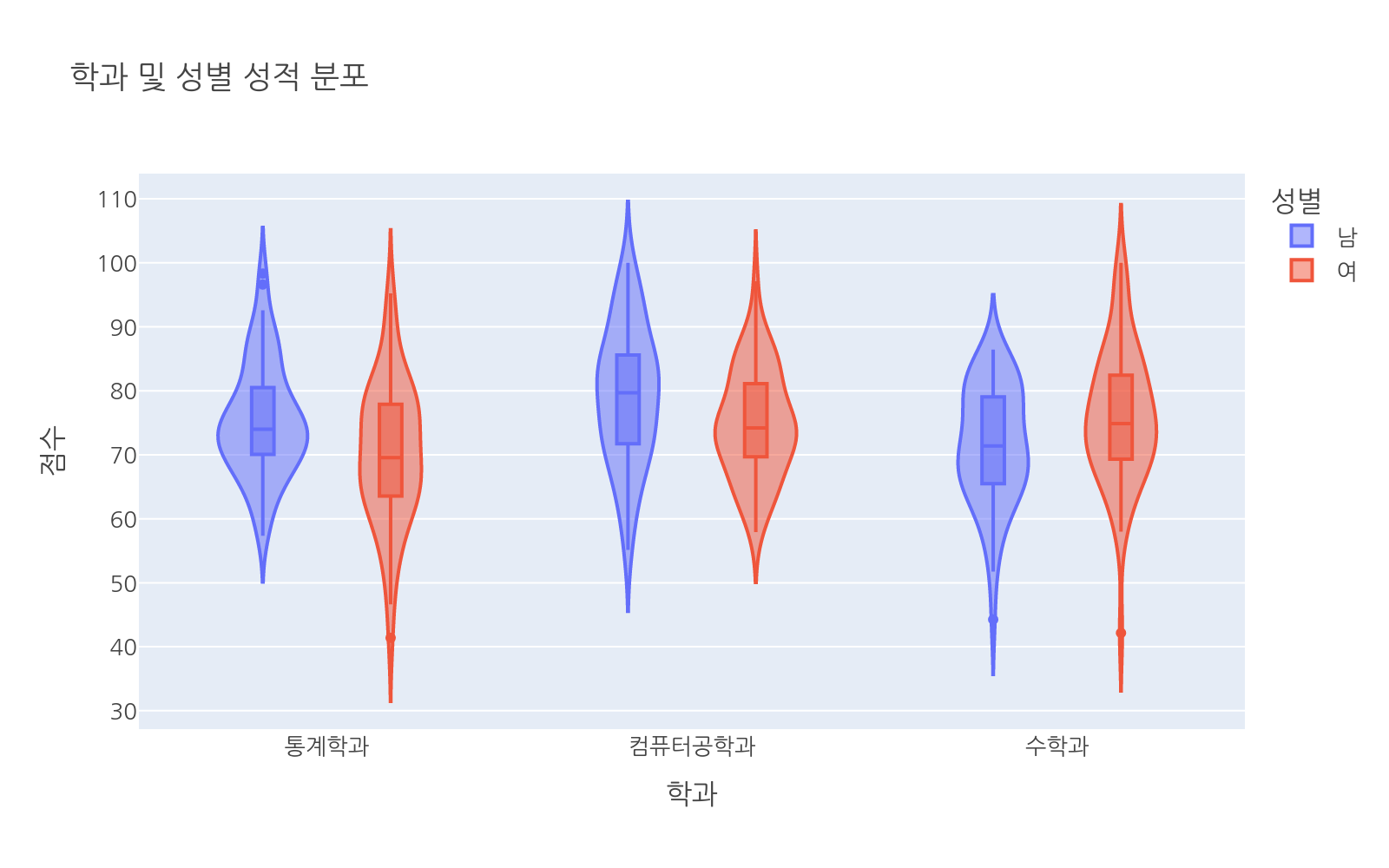
박스플롯 vs 바이올린: 언제 무엇을 쓸까
두 차트는 용도가 비슷하지만 강조점이 다릅니다.
| 상황 | 추천 |
|---|---|
| 이상치 확인이 중요할 때 | 박스플롯 |
| 분포의 형태(봉우리 수, 비대칭)가 중요할 때 | 바이올린 |
| 데이터가 적을 때 (n < 50) | 박스 + points="all" |
| 두 그룹을 간결하게 비교할 때 | 박스플롯 |
| 데이터가 충분하고 밀도 패턴이 중요할 때 | 바이올린 |
준호가 두 차트를 모두 실행해보더니 말했습니다.
"바이올린이 더 예쁜데, 교수님이 보수적이시니까 박스플롯으로 갈게."
지윤이 웃었습니다. 상황에 따라 도구를 고르는 것, 그것도 실력이었습니다.
실전: 학과별 성적 분포 최종
# 파일: grade_box_final.pyimport plotly.express as pximport numpy as npimport pandas as pdnp.random.seed(1)majors = ["통계학과", "컴퓨터공학과", "수학과", "경영학과", "물리학과"]n_per = 80means = [72, 78, 74, 70, 76]stds = [10, 9, 11, 12, 8]data = []for major, mean, std in zip(majors, means, stds): for s in np.random.normal(mean, std, n_per).clip(0, 100): data.append({"major": major, "score": s})df = pd.DataFrame(data)fig = px.box( df, x="major", y="score", color="major", points="outliers", notched=True, # 중앙값 신뢰구간 표시 title="학과별 성적 분포 비교", labels={"major": "학과", "score": "점수"})fig.update_layout( showlegend=False, yaxis_range=[30, 105])fig.show()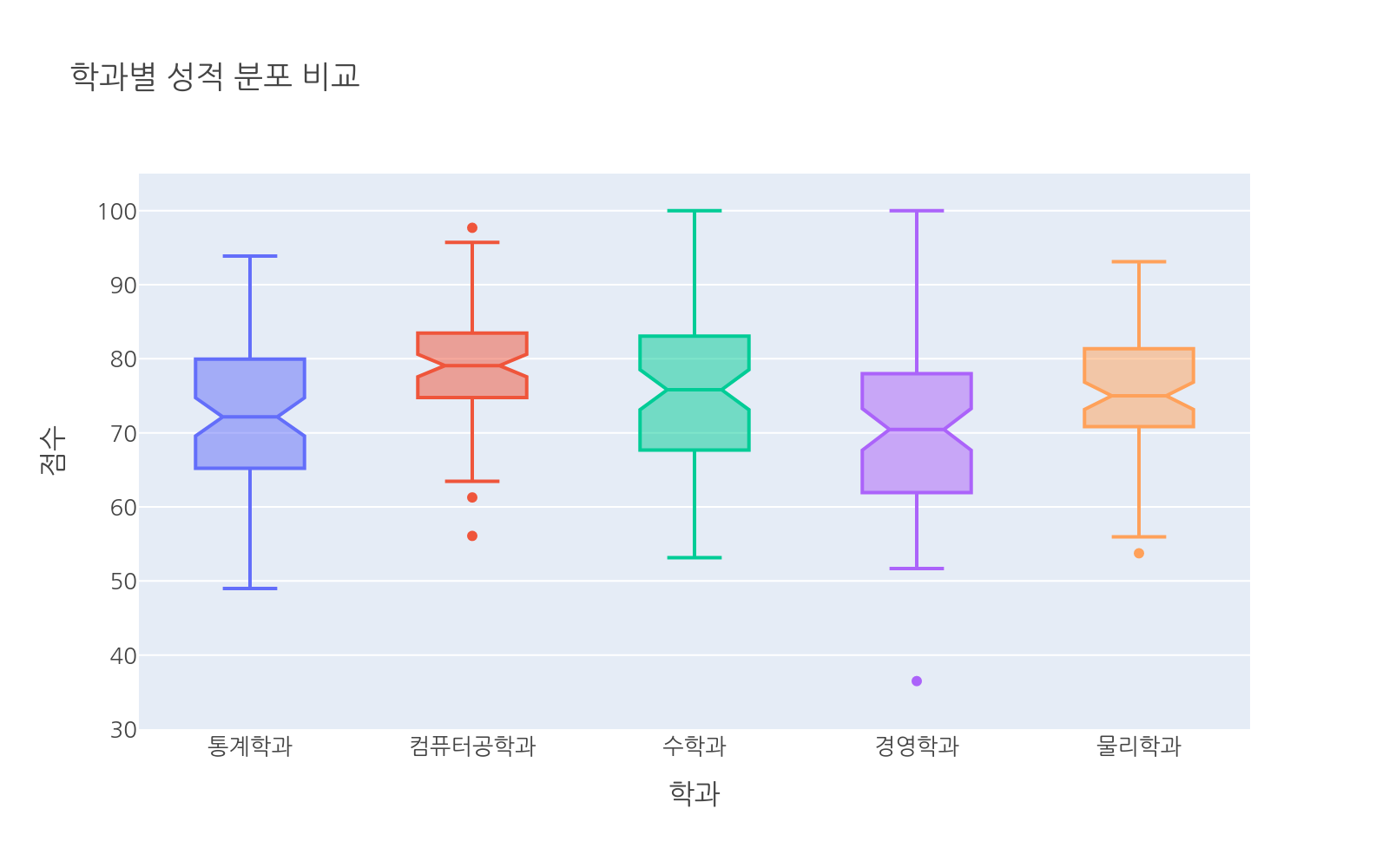
notched=True는 중앙값 주변에 신뢰구간 노치(notch)를 표시합니다. 두 박스의 노치가 겹치지 않으면 중앙값이 통계적으로 유의미하게 다르다는 것을 시각적으로 보여줍니다.