"왜 이 데이터에 이 차트를 선택했나요?"
교수님의 질문이 강의실에 울렸습니다. 지윤은 생각을 정리했습니다. 도구를 쓰는 것과 왜 그 도구를 선택했는지를 설명하는 것은 다른 일이었습니다.
"데이터가 어떤 이야기를 하려는지에 따라 차트를 골랐습니다."
지윤이 차분하게 설명을 시작했습니다.
데이터 유형별 차트 추천
차트 선택의 가장 기본은 데이터가 무엇을 보여주려 하는지 파악하는 것입니다.
시간에 따른 변화
값이 시간 흐름에 따라 어떻게 달라지는지 보여줄 때입니다.
# 파일: chart_guide_line.pyimport plotly.express as pximport pandas as pddf = px.data.stocks().melt(id_vars="date", var_name="company", value_name="price")fig = px.line( df, x="date", y="price", color="company", title="주가 변화 → 선 그래프", labels={"date": "날짜", "price": "주가 (정규화)", "company": "기업"})fig.show()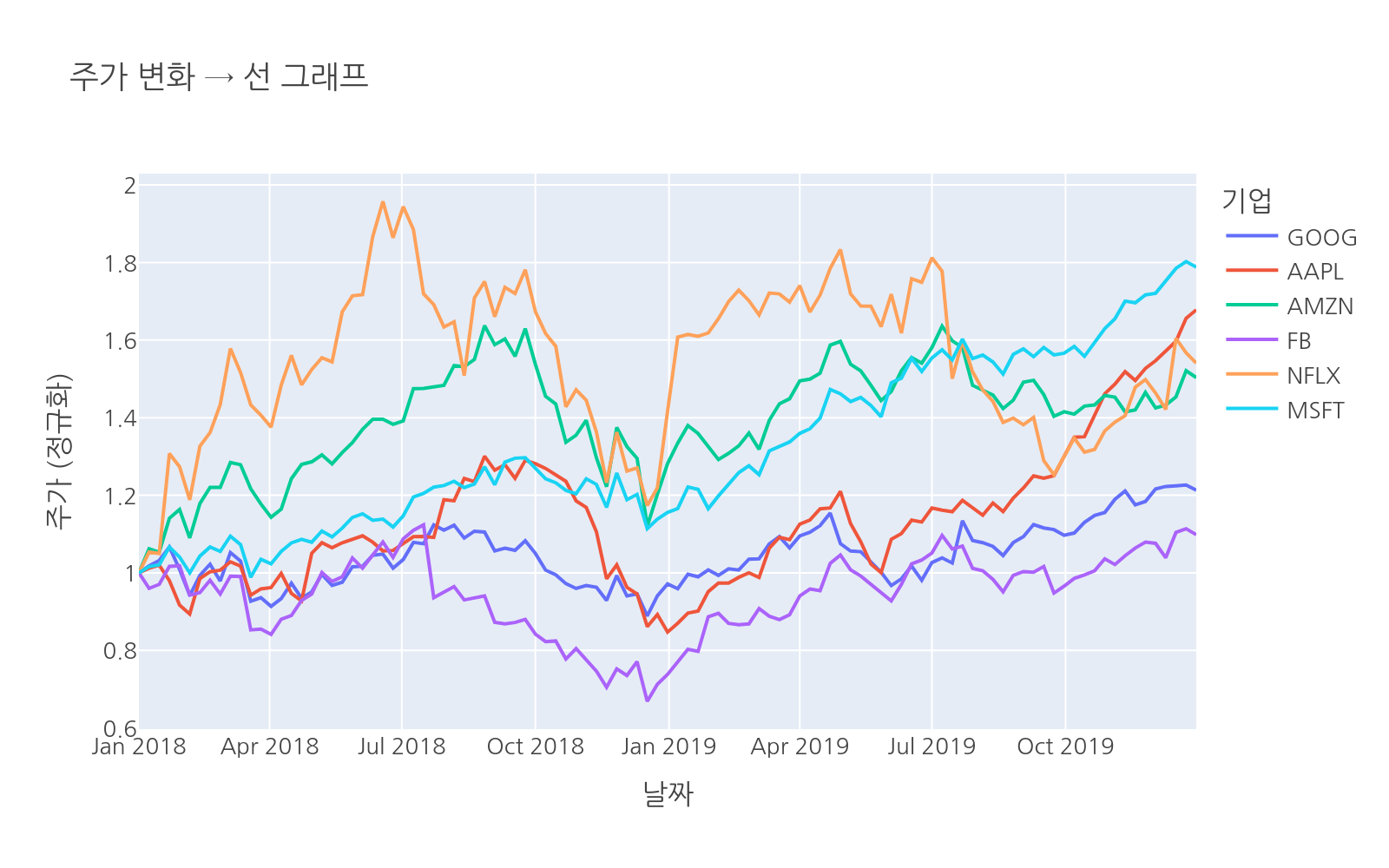
선 그래프는 연속적인 변화를 가장 직관적으로 표현합니다. 여러 시리즈를 함께 그리면 상대적인 변화도 비교할 수 있습니다.
카테고리 비교
항목들 간의 크기를 비교할 때입니다.
# 파일: chart_guide_bar.pyimport plotly.express as pximport pandas as pddf = pd.DataFrame({ "category": ["의류", "식품", "전자기기", "도서", "스포츠"], "sales": [3200, 4100, 5800, 1200, 2700]})fig = px.bar( df, x="category", y="sales", text_auto=True, title="카테고리별 매출 → 막대 그래프", labels={"category": "카테고리", "sales": "매출 (만원)"})fig.show()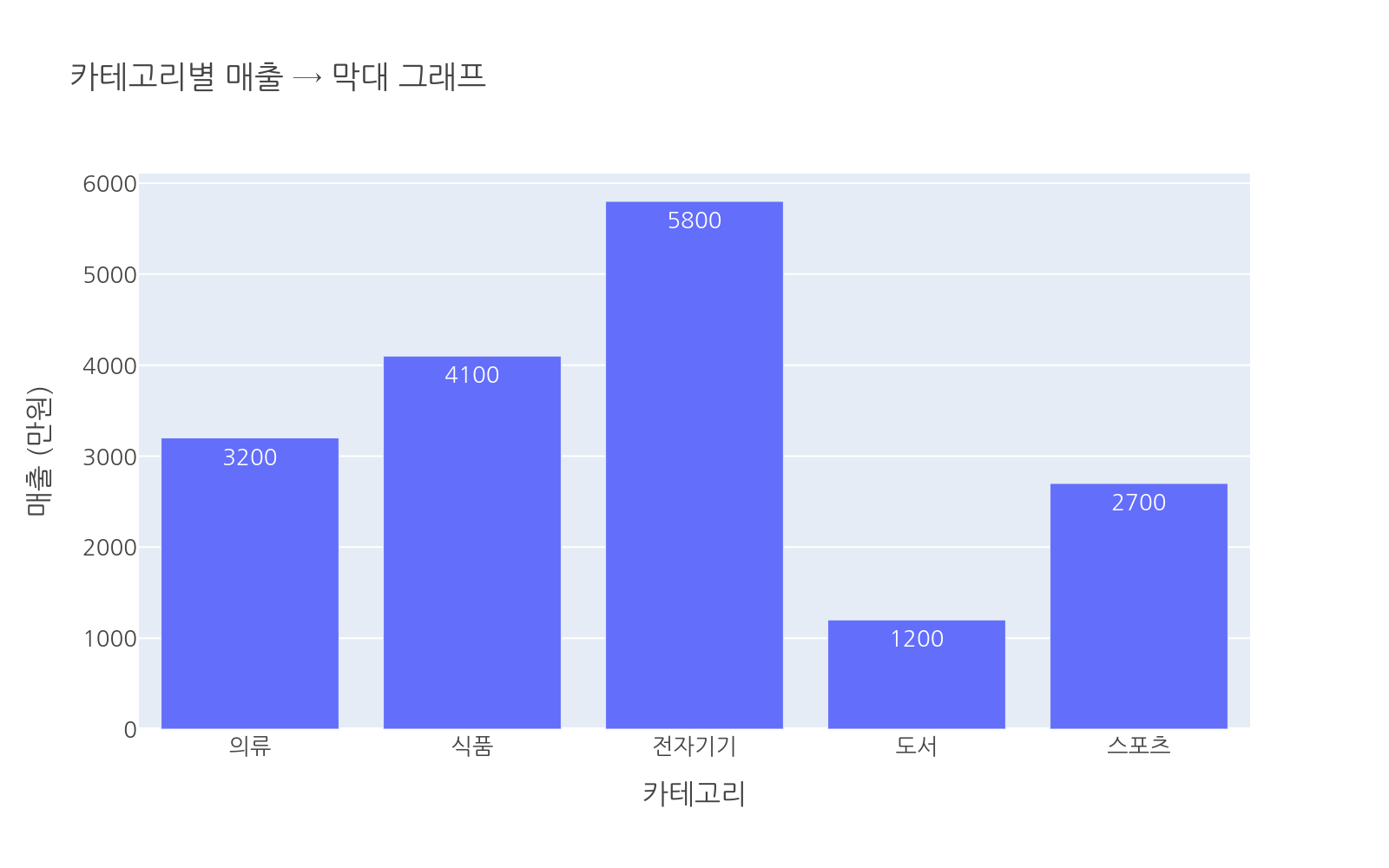
막대 그래프는 각 막대의 끝점을 눈으로 비교하기 쉬워 절대적인 크기 차이를 보여주는 데 적합합니다.
비율과 구성
전체에서 각 부분이 차지하는 비중을 보여줄 때입니다.
# 파일: chart_guide_pie.pyimport plotly.express as pximport pandas as pddf = pd.DataFrame({ "label": ["의류", "식품", "전자기기", "도서", "스포츠"], "value": [3200, 4100, 5800, 1200, 2700]})fig = px.pie( df, values="value", names="label", hole=0.35, title="카테고리별 매출 비율 → 도넛 차트")fig.update_traces(textinfo="label+percent")fig.show()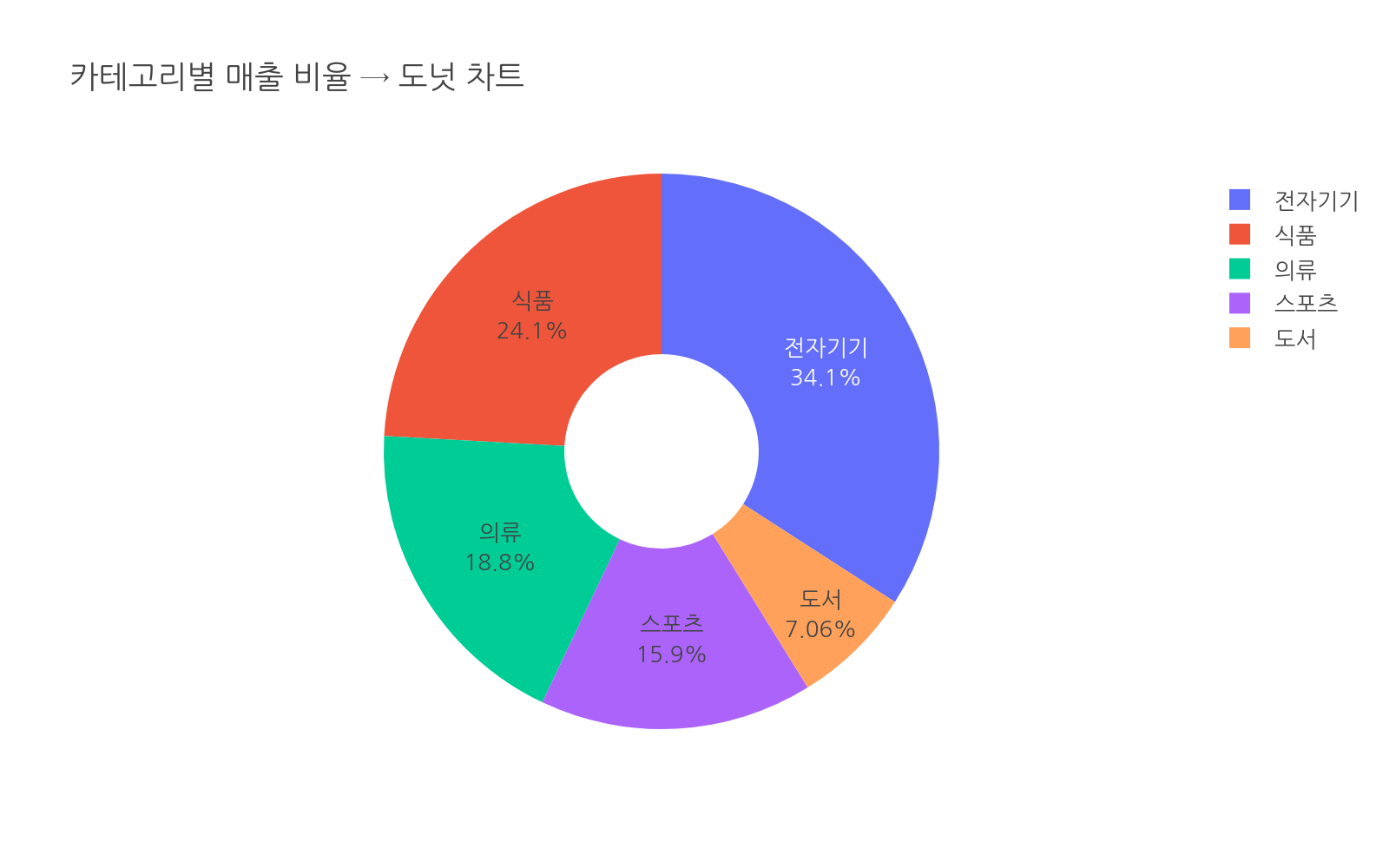
원형/도넛 차트는 전체의 일부임을 시각적으로 강조합니다. 항목이 5개를 넘어가면 막대 그래프가 더 읽기 편합니다.
두 변수의 관계
두 수치형 변수 사이의 관계나 패턴을 볼 때입니다.
# 파일: chart_guide_scatter.pyimport plotly.express as pxdf = px.data.gapminder().query("year == 2007")fig = px.scatter( df, x="gdpPercap", y="lifeExp", color="continent", hover_name="country", log_x=True, title="GDP vs 기대수명 → 산점도", labels={"gdpPercap": "1인당 GDP", "lifeExp": "기대수명", "continent": "대륙"})fig.show()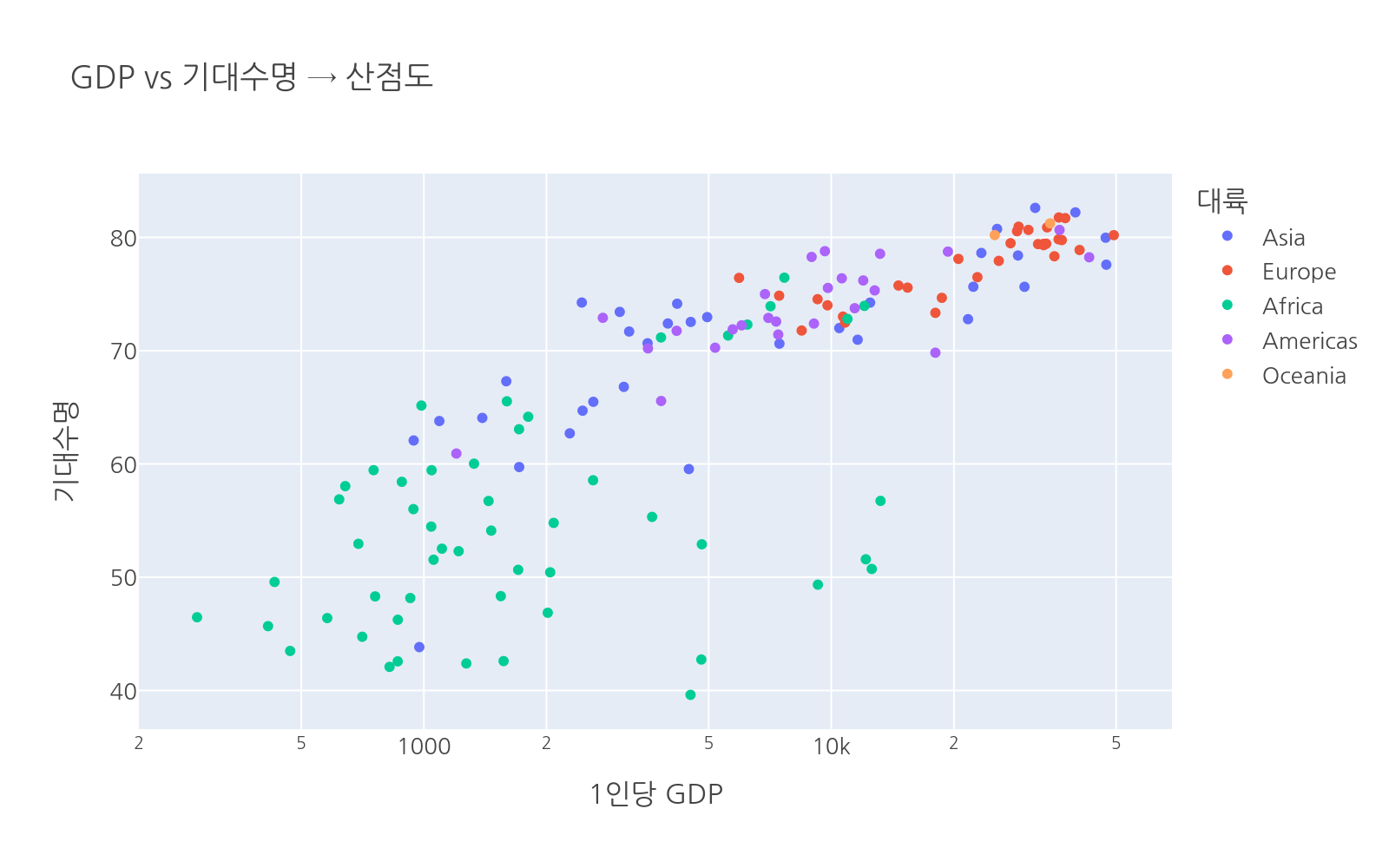
산점도는 두 변수 간의 상관, 군집, 이상치를 한눈에 파악할 수 있습니다.
분포 확인
데이터가 어떤 구간에 어떻게 분포하는지 볼 때입니다.
| 목적 | 추천 차트 |
|---|---|
| 전체 분포 모양 파악 | 히스토그램 |
| 여러 그룹의 분포 핵심 통계 비교 | 박스플롯 |
| 분포 형태 상세 비교 (데이터 충분) | 바이올린 |
| 행렬 형태 수치 패턴 | 히트맵 |
데이터 유형 × 목적 요약표
| 보여주려는 것 | 데이터 형태 | 추천 차트 |
|---|---|---|
| 시간에 따른 변화 | 날짜 + 수치 | 선 그래프 |
| 카테고리 간 절대값 비교 | 범주 + 수치 | 막대 그래프 (수직/수평) |
| 부분 구성 비율 | 범주 + 수치 | 원형/도넛, 스택 막대 |
| 두 수치 관계 | 수치 × 수치 | 산점도 |
| 두 수치 관계 + 크기 정보 | 수치 × 수치 × 수치 | 버블 차트 |
| 단일 그룹 분포 | 수치 | 히스토그램 |
| 여러 그룹 분포 비교 | 범주 + 수치 | 박스플롯, 바이올린 |
| 행렬 패턴 | 행 × 열 수치 | 히트맵 |
Matplotlib vs Plotly: 언제 무엇을
두 라이브러리는 경쟁 관계가 아닙니다. 역할이 다릅니다.
Matplotlib이 더 나은 상황
- 논문이나 보고서에 정적 이미지(.png, .pdf)로 출력할 때
- 픽셀 단위의 세밀한 레이아웃 조정이 필요할 때
- 커스텀 수학 수식, 화살표, 주석이 많이 들어갈 때
- seaborn, scipy, statsmodels와 함께 쓸 때
# Matplotlib: 논문용 정적 차트import matplotlib.pyplot as pltimport numpy as npx = np.linspace(0, 2 * np.pi, 100)plt.figure(figsize=(8, 4))plt.plot(x, np.sin(x), label="sin(x)")plt.plot(x, np.cos(x), label="cos(x)")plt.xlabel("x")plt.ylabel("y")plt.title("sin and cos")plt.legend()plt.tight_layout()plt.savefig("trig_functions.png", dpi=300)plt.show()Plotly가 더 나은 상황
- 웹 브라우저에서 인터랙티브하게 탐색할 때
- 발표 슬라이드에서 질문에 즉석으로 답할 때
- 대시보드나 웹 앱을 만들 때 (Dash, Streamlit)
- 여러 사람과 HTML로 공유할 때
# Plotly: 인터랙티브 탐색용import plotly.express as pximport numpy as npimport pandas as pdx = np.linspace(0, 2 * np.pi, 100)df = pd.DataFrame({ "x": np.concatenate([x, x]), "y": np.concatenate([np.sin(x), np.cos(x)]), "func": ["sin(x)"] * 100 + ["cos(x)"] * 100})fig = px.line(df, x="x", y="y", color="func", title="sin and cos")fig.show()
두 코드는 같은 데이터를 표현하지만, Plotly 버전은 마우스로 확대하고 특정 값을 바로 읽을 수 있습니다.
같은 데이터, 다른 차트
같은 데이터를 여러 차트로 표현해보면 각 차트가 무엇을 강조하는지 선명해집니다.
# 파일: same_data_different_charts.pyimport plotly.express as pximport numpy as npimport pandas as pdfrom plotly.subplots import make_subplotsimport plotly.graph_objects as gonp.random.seed(3)majors = ["A학과", "B학과", "C학과"]n = 60means = [72, 78, 68]stds = [10, 7, 14]data = []for major, mean, std in zip(majors, means, stds): for s in np.random.normal(mean, std, n).clip(0, 100): data.append({"major": major, "score": s})df = pd.DataFrame(data)# 3개 차트를 나란히 배치fig = make_subplots( rows=1, cols=3, subplot_titles=["히스토그램", "박스플롯", "바이올린"])colors = px.colors.qualitative.Plotlyfor i, major in enumerate(majors): d = df[df["major"] == major]["score"] color = colors[i] # 히스토그램 fig.add_trace( go.Histogram(x=d, name=major, marker_color=color, opacity=0.6, showlegend=(i == 0)), row=1, col=1 ) # 박스플롯 fig.add_trace( go.Box(y=d, name=major, marker_color=color, showlegend=False), row=1, col=2 ) # 바이올린 fig.add_trace( go.Violin(y=d, name=major, line_color=color, box_visible=True, showlegend=False), row=1, col=3 )fig.update_layout( title="같은 데이터, 다른 차트", barmode="overlay", height=450)fig.show()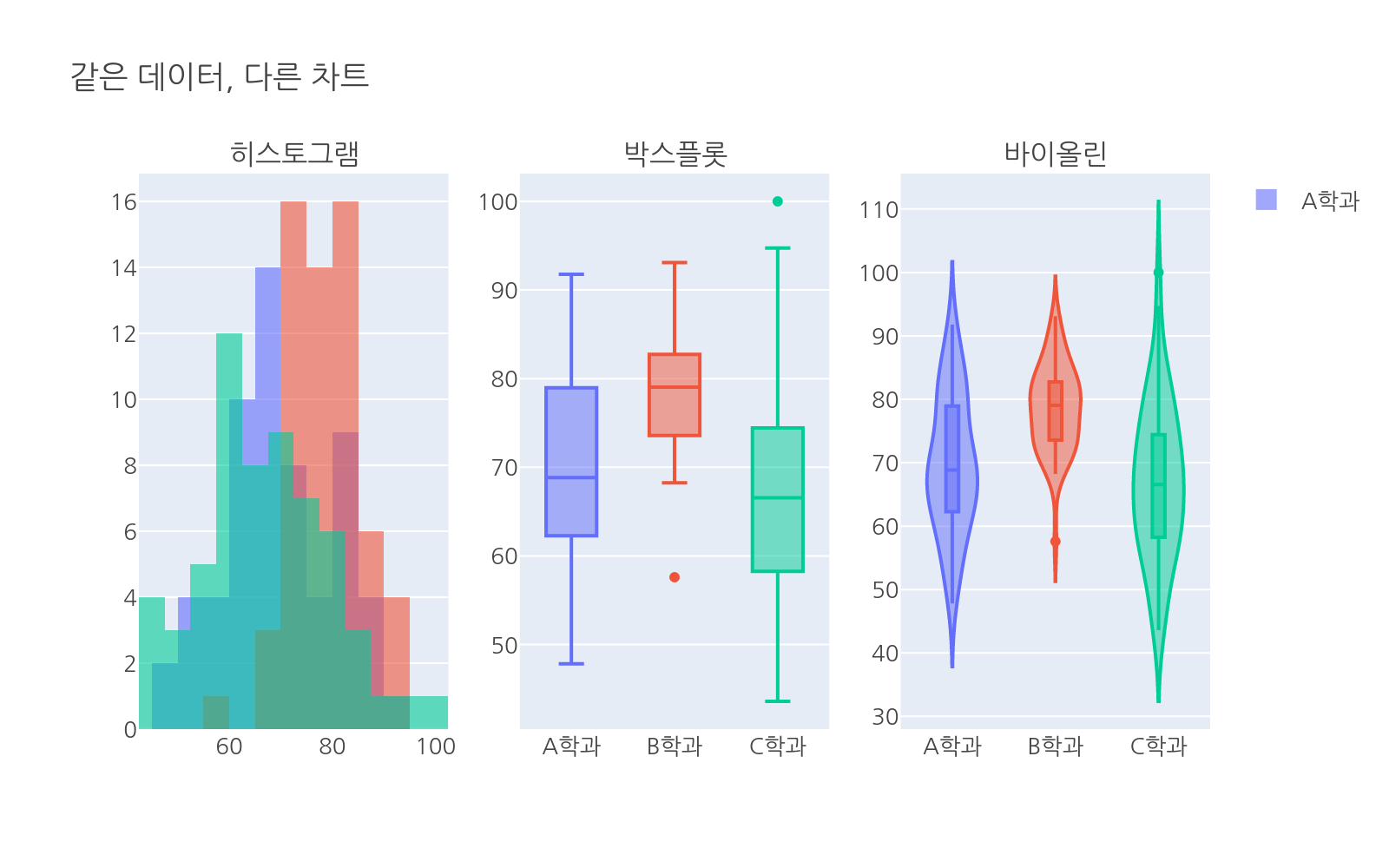
히스토그램은 B학과의 데이터가 좁게 집중되어 있음을 보여주고, 박스플롯은 C학과의 이상치와 넓은 범위를 강조하고, 바이올린은 A학과의 분포 형태를 상세히 나타냅니다.
정리
지윤이 교수님의 질문에 마지막으로 답했습니다.
"민수의 시계열 데이터는 시간에 따른 변화를 보여야 해서 선 그래프를 골랐습니다. 하은의 설문 데이터는 응답 비율이 핵심이라 도넛 차트를 사용했습니다. 준호의 분포 분석은 여러 그룹을 한 번에 비교해야 해서 박스플롯이 적합했습니다."
교수님이 고개를 끄덕였습니다.
"차트를 선택할 때는 항상 이 두 가지를 먼저 물어보세요. '내 데이터는 어떤 구조인가?' 그리고 '나는 무엇을 전달하려 하는가?' 그 두 질문에 답하면 차트는 자연스럽게 따라옵니다."
빠른 참조
| 질문 | 차트 |
|---|---|
| 시간이 흐르면서 어떻게 변했나? | 선 그래프 |
| 어떤 항목이 가장 크거나 작나? | 막대 그래프 |
| 각 부분이 전체의 몇 %인가? | 원형/도넛 차트 |
| A가 높으면 B도 높은가? | 산점도 |
| 데이터가 어디에 몰려 있나? | 히스토그램 |
| 여러 그룹의 중앙값과 범위를 비교하려면? | 박스플롯 |
| 분포 형태를 자세히 보고 싶다면? | 바이올린 |
| 행렬 데이터의 패턴을 보려면? | 히트맵 |
| 정적 이미지로 저장해야 한다면? | Matplotlib |
| 인터랙티브하게 탐색하거나 공유하려면? | Plotly |