groupby와 pivot_table 시각화
앞 절에서는 DataFrame을 그대로 px 함수에 넣었습니다. 이번에는 한 단계 더 나아갑니다. 데이터를 집계하고, 그 결과를 차트로 만드는 것입니다.
지윤은 팀원 민지에게 물었습니다. "요일별로 팁 평균 내야 하는데, groupby 결과를 그냥 넣어도 돼?"
민지가 노트북을 들여다보며 고개를 끄덕였습니다. "groupby 결과가 DataFrame이면 돼. 문제는 index를 reset해야 한다는 거야."
집계 결과를 시각화할 때 가장 흔히 하는 실수가 바로 인덱스를 그대로 두는 것입니다.
groupby().agg() 결과를 px.bar()로
# 새 파일: chapter04_02_groupby.pyimport plotly.express as pximport pandas as pddf = px.data.tips()# groupby 집계grouped = df.groupby("day")["tip"].agg(["mean", "sum", "count"])print(grouped)print(type(grouped))출력 결과를 보면 인덱스가 day 열입니다.
mean sum count
day
Fri 2.73 51.96 19
Sat 2.99 260.40 87
Sun 3.25 247.39 76
Thur 2.77 171.83 62
이 상태로 px.bar()에 넣으면 x 파라미터에 day가 보이지 않습니다. reset_index()로 인덱스를 일반 열로 바꿔야 합니다.
# 수정: chapter04_02_groupby.pyimport plotly.express as pximport pandas as pddf = px.data.tips()grouped = df.groupby("day")["tip"].agg(["mean", "sum", "count"])# reset_index()로 인덱스를 열로 변환grouped = grouped.reset_index()grouped.columns = ["day", "평균팁", "총팁", "건수"]# 요일 순서 지정day_order = ["Thur", "Fri", "Sat", "Sun"]fig = px.bar( grouped, x="day", y="평균팁", text="평균팁", category_orders={"day": day_order}, color="평균팁", color_continuous_scale="Blues", title="요일별 평균 팁")fig.update_traces(texttemplate="%{text:.2f}", textposition="outside")fig.show()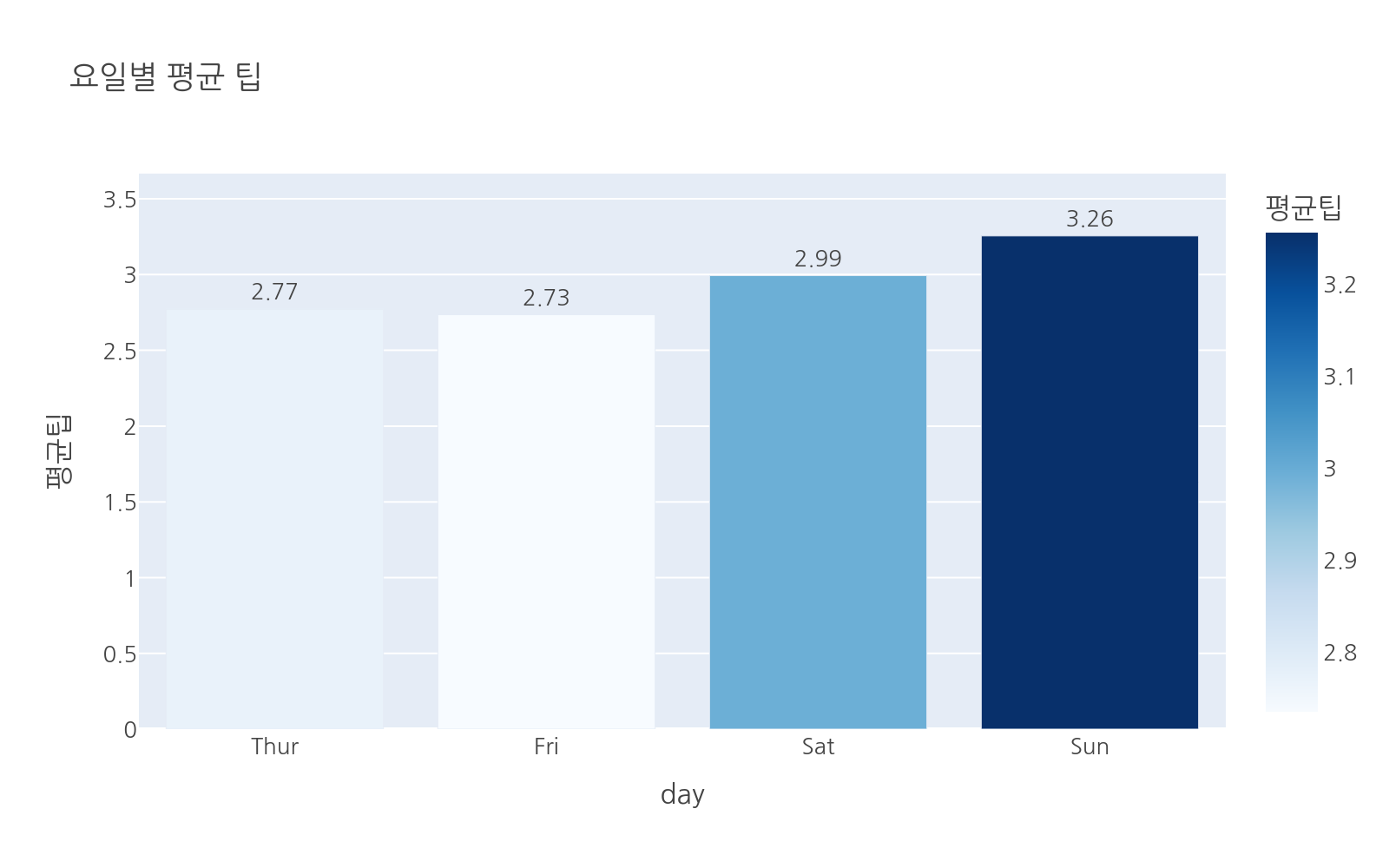
실행하면 Blues 컬러 스케일이 적용된 요일별 평균 팁 막대 그래프가 나타납니다. 각 막대 위에 소수점 둘째 자리까지 값이 표시되며, 일요일(Sun)의 평균 팁이 가장 높습니다.
text="평균팁"으로 막대 위에 값을 표시하고, texttemplate="%{text:.2f}"로 소수점 둘째 자리까지 보이도록 합니다.
pivot_table 결과를 px.imshow()로 히트맵 만들기
pivot_table()은 두 카테고리를 행과 열로 펼쳐 매트릭스를 만듭니다. 이 결과를 px.imshow()로 넘기면 바로 히트맵이 됩니다.
# 수정: chapter04_02_groupby.pyimport plotly.express as pximport pandas as pddf = px.data.tips()grouped = df.groupby("day")["tip"].agg(["mean", "sum", "count"])grouped = grouped.reset_index()grouped.columns = ["day", "평균팁", "총팁", "건수"]day_order = ["Thur", "Fri", "Sat", "Sun"]fig = px.bar( grouped, x="day", y="평균팁", text="평균팁", category_orders={"day": day_order}, color="평균팁", color_continuous_scale="Blues", title="요일별 평균 팁")fig.update_traces(texttemplate="%{text:.2f}", textposition="outside")fig.show()# pivot_table: 요일 x 성별 조합의 평균 팁pivot = df.pivot_table( values="tip", index="day", columns="sex", aggfunc="mean")pivot = pivot.reindex(day_order) # 요일 순서 맞추기print(pivot)# px.imshow()로 히트맵fig2 = px.imshow( pivot, text_auto=".2f", color_continuous_scale="RdYlGn", title="요일 × 성별 평균 팁 히트맵")fig2.update_layout( xaxis_title="성별", yaxis_title="요일")fig2.show()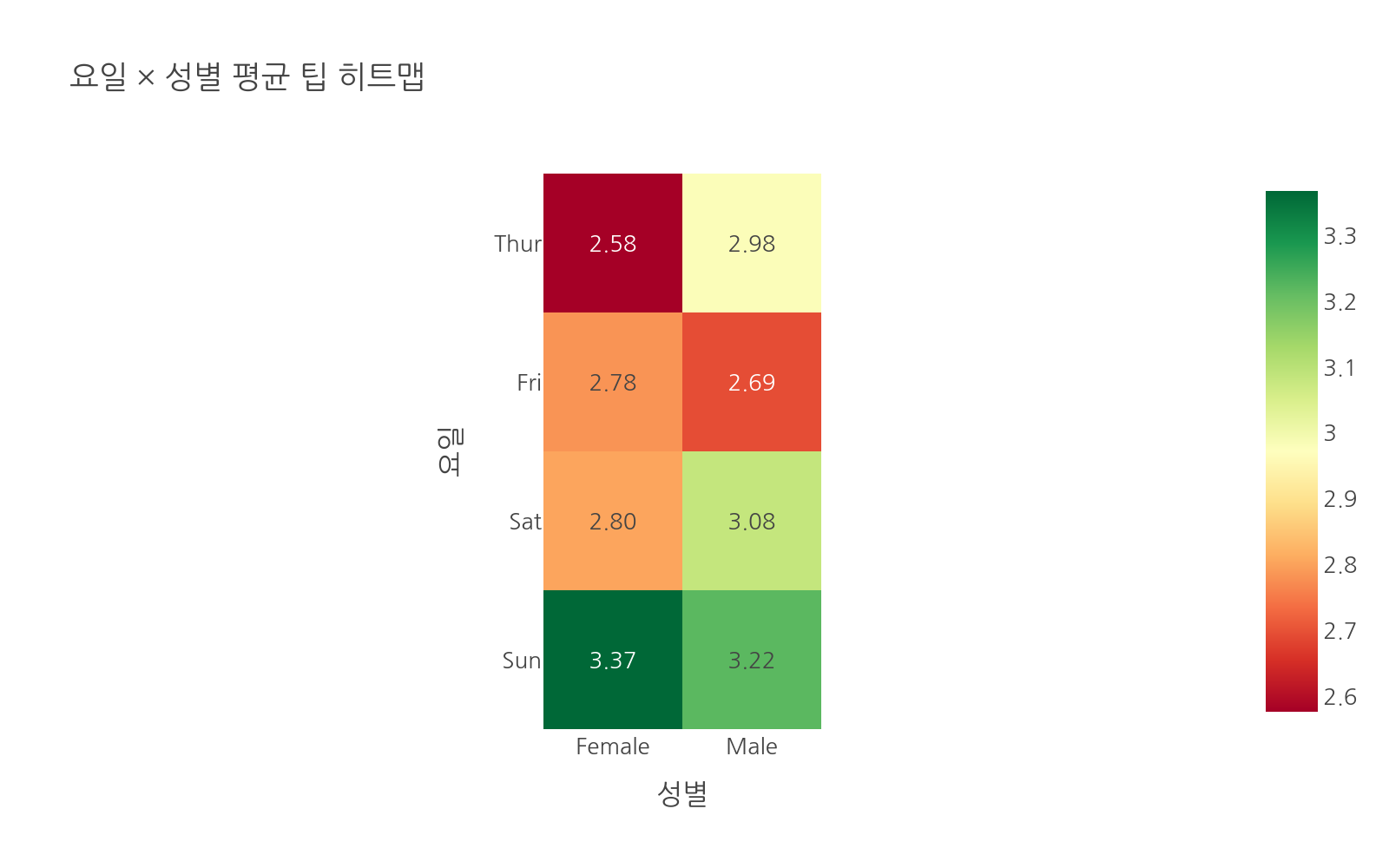
실행하면 요일과 성별 조합의 평균 팁을 색과 숫자로 동시에 보여주는 히트맵이 나타납니다. 초록색이 높은 팁, 빨간색이 낮은 팁을 나타냅니다.
text_auto=".2f"를 주면 각 셀 안에 값이 자동으로 표시됩니다. 두 카테고리의 조합을 한눈에 비교할 때 히트맵이 가장 효과적입니다.
value_counts()를 px.pie()로 파이 차트 만들기
value_counts()의 결과는 Series입니다. reset_index()로 DataFrame으로 바꾼 뒤 사용합니다.
# 수정: chapter04_02_groupby.pyimport plotly.express as pximport pandas as pddf = px.data.tips()grouped = df.groupby("day")["tip"].agg(["mean", "sum", "count"])grouped = grouped.reset_index()grouped.columns = ["day", "평균팁", "총팁", "건수"]day_order = ["Thur", "Fri", "Sat", "Sun"]fig = px.bar( grouped, x="day", y="평균팁", text="평균팁", category_orders={"day": day_order}, color="평균팁", color_continuous_scale="Blues", title="요일별 평균 팁")fig.update_traces(texttemplate="%{text:.2f}", textposition="outside")fig.show()pivot = df.pivot_table( values="tip", index="day", columns="sex", aggfunc="mean")pivot = pivot.reindex(day_order)fig2 = px.imshow( pivot, text_auto=".2f", color_continuous_scale="RdYlGn", title="요일 × 성별 평균 팁 히트맵")fig2.update_layout(xaxis_title="성별", yaxis_title="요일")fig2.show()# value_counts()로 요일별 방문 비율 파이 차트day_counts = df["day"].value_counts().reset_index()day_counts.columns = ["day", "count"]fig3 = px.pie( day_counts, names="day", values="count", hole=0.4, # 도넛 차트 category_orders={"day": day_order}, title="요일별 방문 비율")fig3.update_traces(textposition="inside", textinfo="percent+label")fig3.show()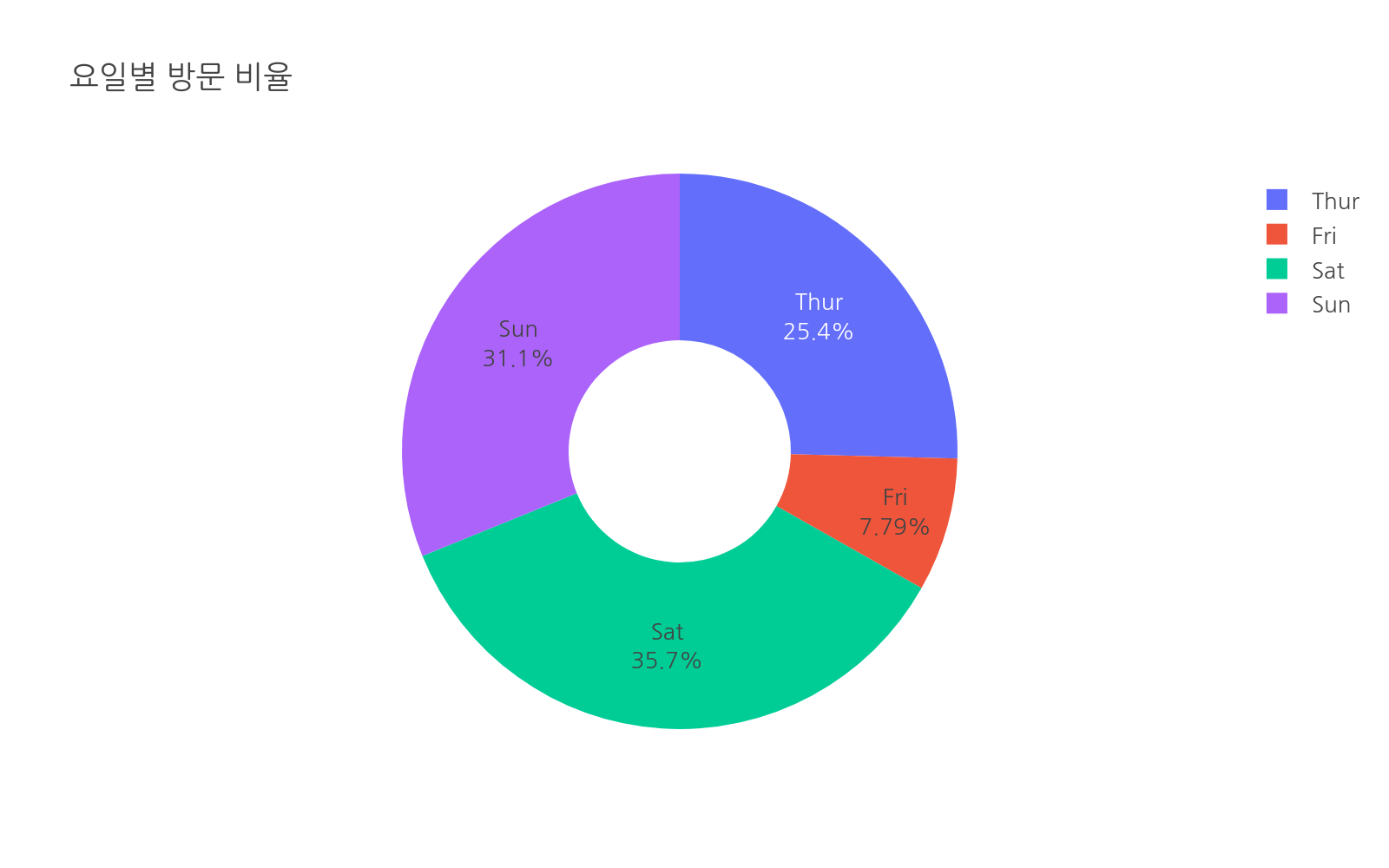
실행하면 요일별 방문 비율을 보여주는 도넛 차트가 나타납니다. Sat(토요일)의 방문 비율이 35.7%로 가장 높고, Fri(금요일)가 7.79%로 가장 낮습니다.
hole=0.4를 주면 파이 차트 가운데가 뚫린 도넛 차트가 됩니다. 비율을 보여줄 때 도넛 차트가 파이 차트보다 시각적으로 깔끔한 경우가 많습니다.
resample() 시계열 집계 후 px.line()으로 선 그래프 그리기
시계열 데이터는 날짜 인덱스로 집계하는 resample()을 자주 씁니다.
# 수정: chapter04_02_groupby.pyimport plotly.express as pximport pandas as pdimport numpy as npdf = px.data.tips()grouped = df.groupby("day")["tip"].agg(["mean", "sum", "count"])grouped = grouped.reset_index()grouped.columns = ["day", "평균팁", "총팁", "건수"]day_order = ["Thur", "Fri", "Sat", "Sun"]fig = px.bar( grouped, x="day", y="평균팁", text="평균팁", category_orders={"day": day_order}, color="평균팁", color_continuous_scale="Blues", title="요일별 평균 팁")fig.update_traces(texttemplate="%{text:.2f}", textposition="outside")fig.show()pivot = df.pivot_table( values="tip", index="day", columns="sex", aggfunc="mean")pivot = pivot.reindex(day_order)fig2 = px.imshow( pivot, text_auto=".2f", color_continuous_scale="RdYlGn", title="요일 × 성별 평균 팁 히트맵")fig2.update_layout(xaxis_title="성별", yaxis_title="요일")fig2.show()day_counts = df["day"].value_counts().reset_index()day_counts.columns = ["day", "count"]fig3 = px.pie( day_counts, names="day", values="count", hole=0.4, category_orders={"day": day_order}, title="요일별 방문 비율")fig3.update_traces(textposition="inside", textinfo="percent+label")fig3.show()# 시계열 데이터 생성 (2023년 1년치 가상 매출)np.random.seed(42)date_range = pd.date_range(start="2023-01-01", end="2023-12-31", freq="D")sales_df = pd.DataFrame({ "date": date_range, "sales": np.random.normal(loc=100, scale=20, size=len(date_range)).clip(50, 200)})sales_df = sales_df.set_index("date")# 월별 집계 (resample) — named aggregation 사용monthly = sales_df.resample("ME").agg( 월평균=("sales", "mean"), 월합계=("sales", "sum"))monthly = monthly.reset_index()monthly["month"] = monthly["date"].dt.strftime("%Y-%m")fig4 = px.line( monthly, x="month", y="월평균", markers=True, title="2023년 월별 평균 매출")fig4.update_layout(xaxis_title="월", yaxis_title="평균 매출")fig4.show()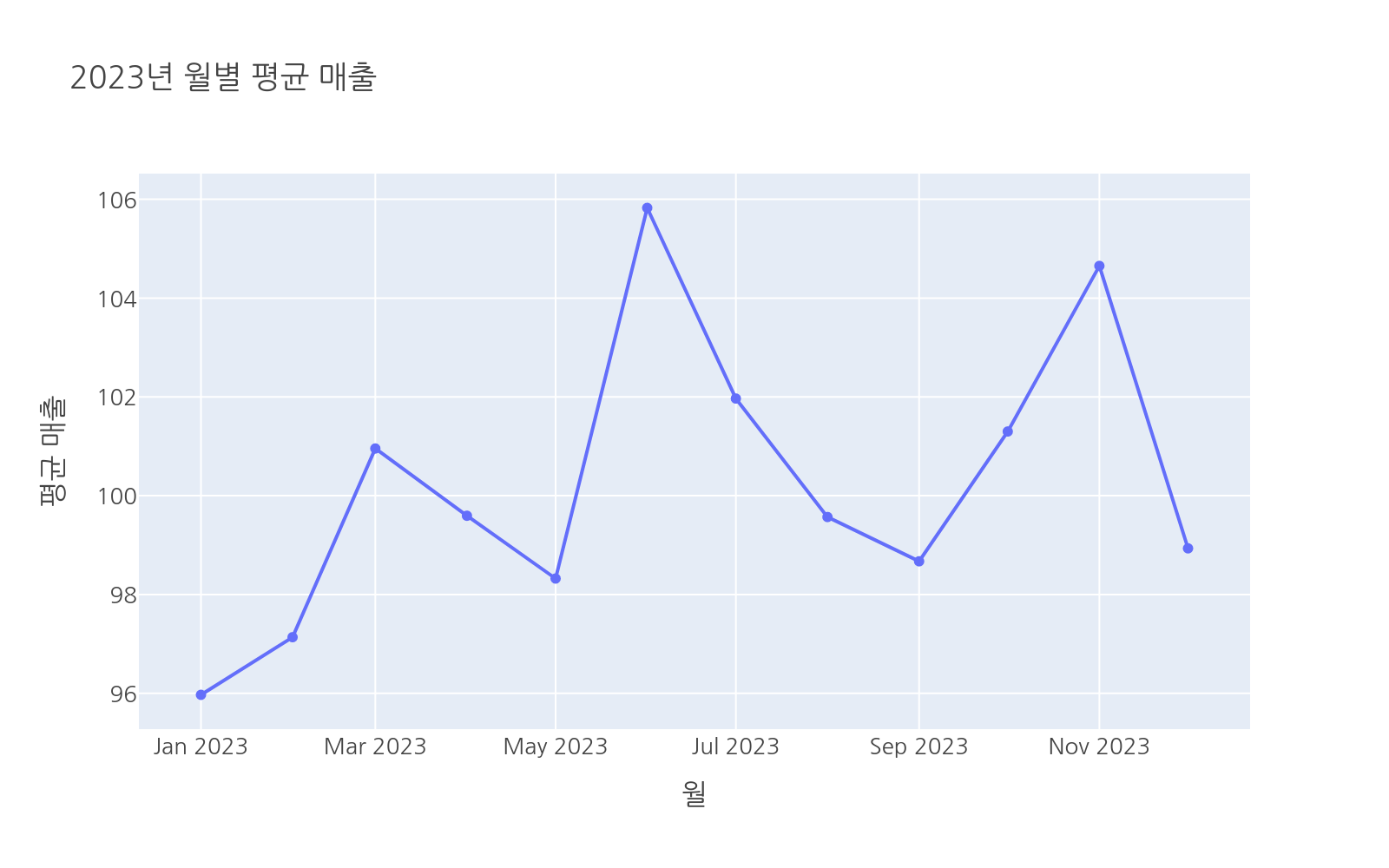
실행하면 2023년 월별 평균 매출 추이를 보여주는 선 그래프가 나타납니다. 마커가 표시되어 각 월의 정확한 값을 확인할 수 있습니다.
resample("ME")는 월말(Month End) 기준으로 집계합니다. 주별은 "W", 분기별은 "QE"를 사용합니다.
실전: tips 데이터를 요일/성별로 집계해서 시각화하기
지금까지 배운 내용을 하나의 파일로 정리합니다.
# 새 파일: chapter04_02_tips_analysis.pyimport plotly.express as pximport plotly.graph_objects as gofrom plotly.subplots import make_subplotsimport pandas as pddf = px.data.tips()day_order = ["Thur", "Fri", "Sat", "Sun"]# 1. 요일별 평균 팁day_avg = df.groupby("day")["tip"].mean().reset_index()day_avg.columns = ["day", "평균팁"]day_avg = day_avg.set_index("day").reindex(day_order).reset_index()# 2. 요일 × 성별 총 팁day_sex = df.groupby(["day", "sex"])["tip"].sum().reset_index()day_sex.columns = ["day", "sex", "총팁"]# 3. 서브플롯으로 한 화면에 배치fig = make_subplots( rows=1, cols=2, subplot_titles=["요일별 평균 팁", "요일·성별 총 팁"])# 왼쪽: 막대 그래프for _, row in day_avg.iterrows(): fig.add_trace( go.Bar(x=[row["day"]], y=[row["평균팁"]], name=row["day"], showlegend=False), row=1, col=1 )# 오른쪽: 그룹 막대 그래프for sex in ["Male", "Female"]: subset = day_sex[day_sex["sex"] == sex] subset = subset.set_index("day").reindex(day_order).reset_index() fig.add_trace( go.Bar(x=subset["day"], y=subset["총팁"], name=sex), row=1, col=2 )fig.update_layout( title="Tips 데이터 집계 분석", barmode="group", height=400)fig.show()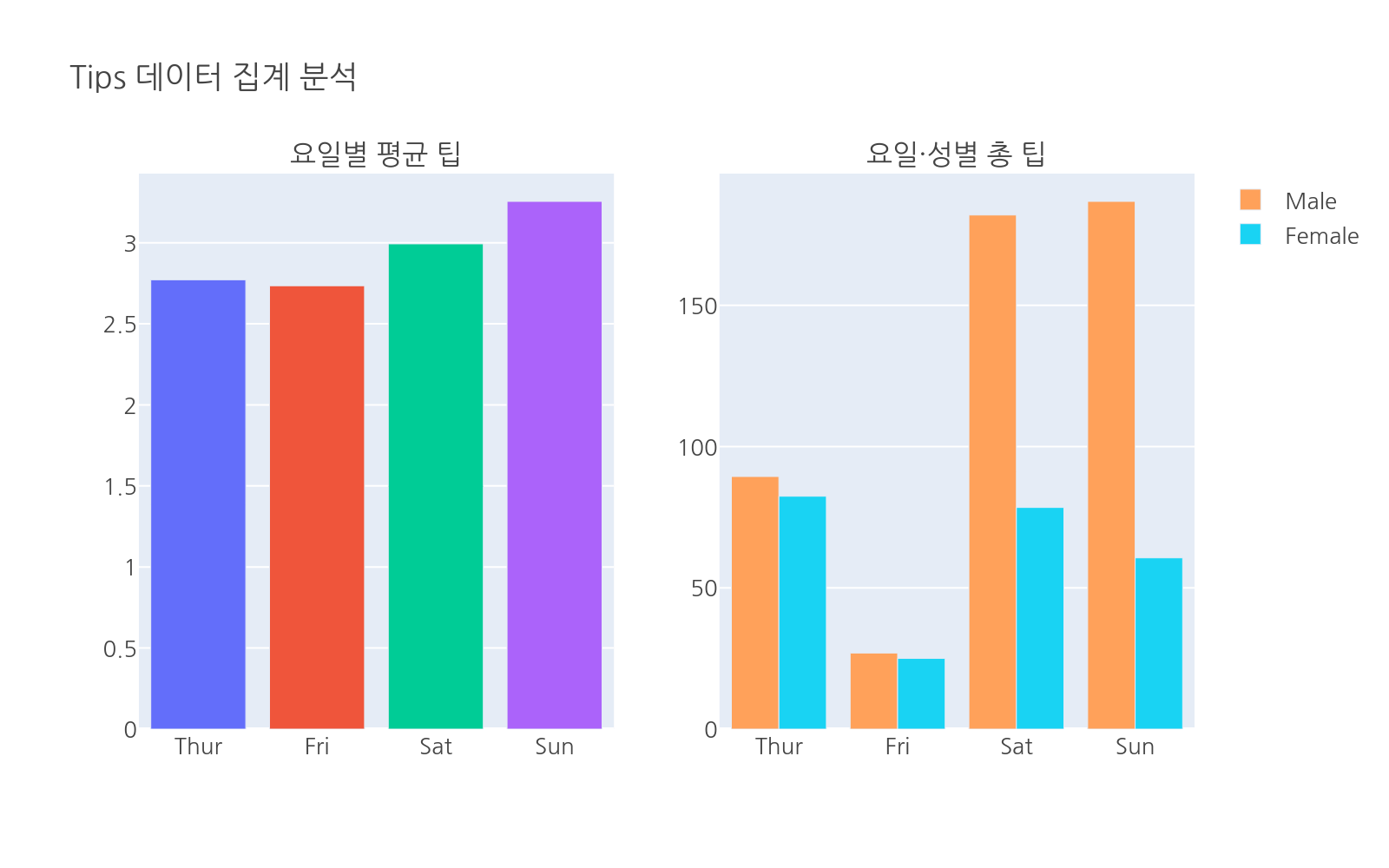
실행하면 요일별 평균 팁과 요일·성별 총 팁을 나란히 보여주는 서브플롯이 나타납니다. 두 가지 시각을 한 화면에 담아 비교하기 편합니다.
make_subplots와 groupby를 조합하면 여러 시각을 한 화면에 담을 수 있습니다. 발표 슬라이드 한 장에 두 가지 인사이트를 함께 보여주는 효과입니다.