Matplotlib vs Seaborn
"선배, 정말 코드가 절반으로 줄어요?"
민서는 반신반의했습니다. Matplotlib으로 겨우 그래프 그리는 법을 익혔는데, 또 새로운 라이브러리를 배워야 한다는 게 내키지 않았습니다.
강주원 선배가 노트북을 가져와서 나란히 코드를 작성하기 시작했습니다. 같은 데이터, 같은 그래프, 두 가지 방법으로.
데이터는 Seaborn에 내장된 tips 데이터셋입니다. 식당에서 수집한 244개의 팁 기록으로, 총 금액, 팁 금액, 성별, 흡연 여부, 요일, 시간대, 인원수가 담겨 있습니다. 민서의 프로젝트와 딱 맞는 데이터였습니다.
산점도 비교
먼저 총 금액(total_bill)과 팁(tip)의 관계를 성별(sex)로 구분해서 그려봤습니다.
Matplotlib으로 그리면 이렇습니다.
import matplotlib.pyplot as pltimport pandas as pdimport seaborn as snstips = sns.load_dataset("tips")# 성별로 데이터 분리male = tips[tips["sex"] == "Male"]female = tips[tips["sex"] == "Female"]fig, ax = plt.subplots(figsize=(8, 5))ax.scatter(male["total_bill"], male["tip"], label="Male", alpha=0.6, color="steelblue")ax.scatter(female["total_bill"], female["tip"], label="Female", alpha=0.6, color="salmon")ax.set_xlabel("Total Bill")ax.set_ylabel("Tip")ax.set_title("Total Bill vs Tip by Sex")ax.legend()plt.show()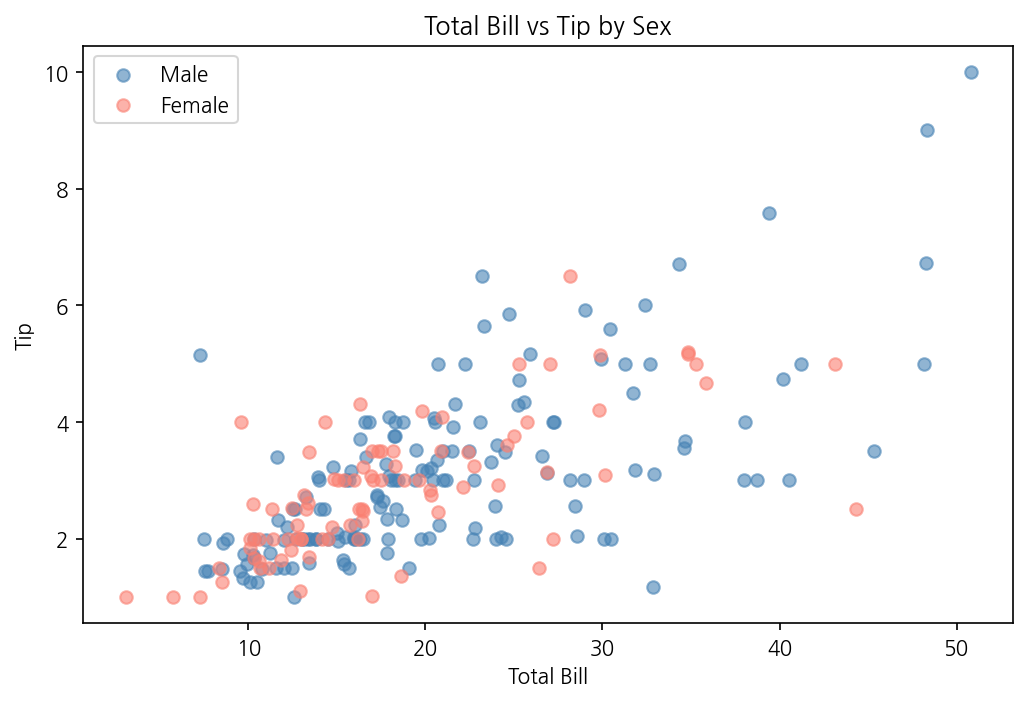
Seaborn으로 그리면 이렇습니다.
import seaborn as snsimport matplotlib.pyplot as plttips = sns.load_dataset("tips")sns.scatterplot(data=tips, x="total_bill", y="tip", hue="sex")plt.title("Total Bill vs Tip by Sex")plt.show()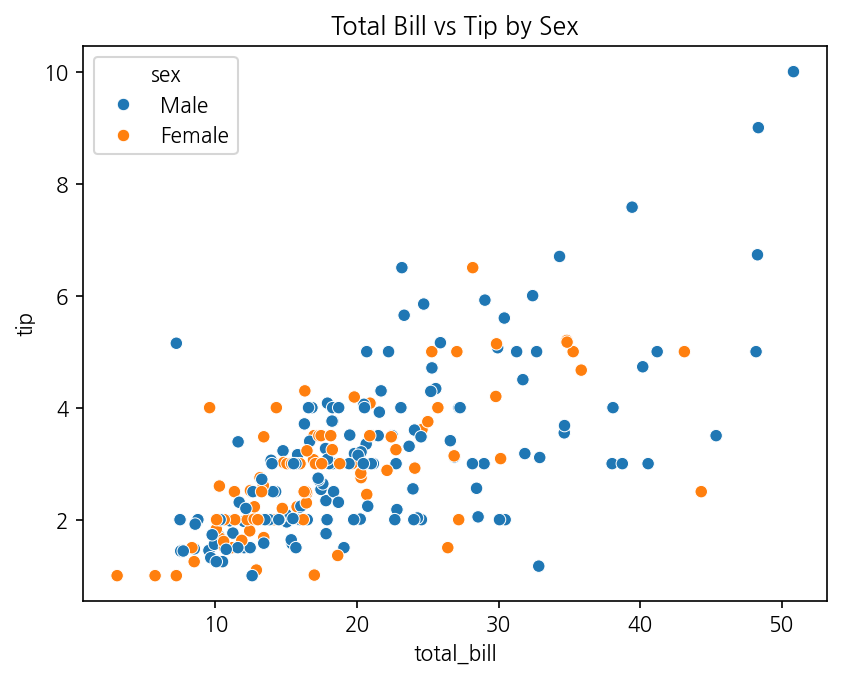
민서가 두 코드를 비교했습니다.
"선배, 진짜 줄었네요. 데이터 분리도 안 하고, 색상도 자동으로 잡히고..."
Matplotlib은 성별 데이터를 직접 분리해서 두 번 scatter를 호출했습니다. Seaborn은 hue="sex" 하나로 끝입니다. 색상도, 범례도 자동입니다.
막대 그래프 비교
다음은 요일별 평균 팁을 막대 그래프로 그려봤습니다. 평균뿐 아니라 불확실성도 보여주고 싶었습니다.
Matplotlib으로 그리면 이렇습니다.
import matplotlib.pyplot as pltimport numpy as npimport seaborn as snstips = sns.load_dataset("tips")days = tips["day"].unique()means = []errors = []for day in days: group = tips[tips["day"] == day]["tip"] means.append(group.mean()) # 95% 신뢰구간 근사 errors.append(1.96 * group.std() / np.sqrt(len(group)))fig, ax = plt.subplots(figsize=(8, 5))ax.bar(days, means, yerr=errors, capsize=4, color="steelblue", alpha=0.7)ax.set_xlabel("Day")ax.set_ylabel("Mean Tip")ax.set_title("Mean Tip by Day")plt.show()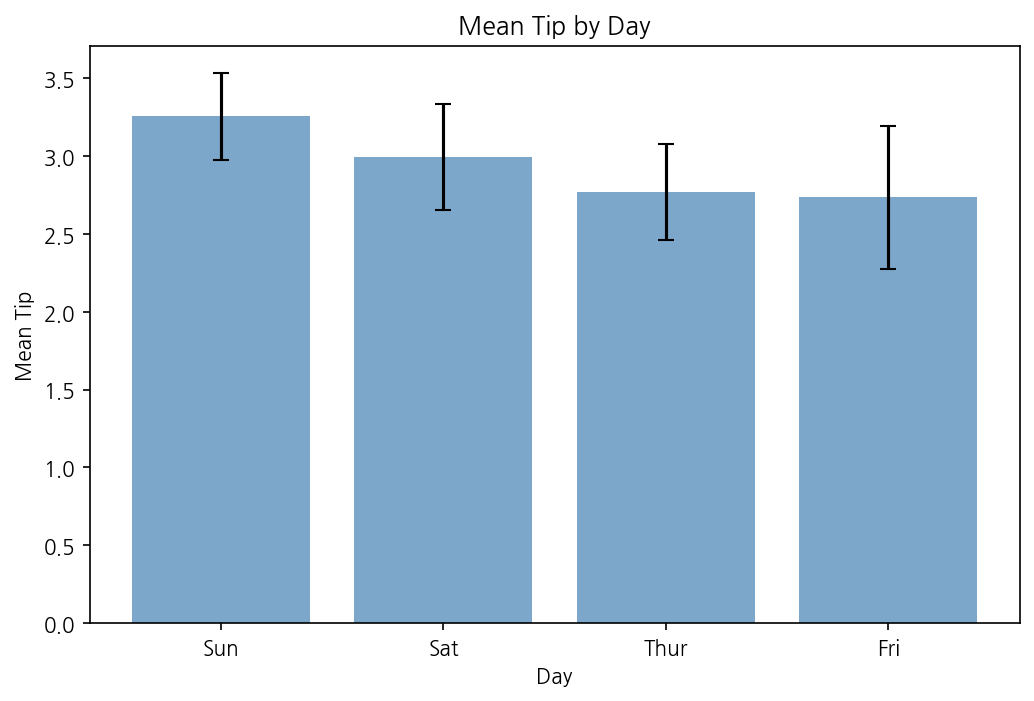
Seaborn으로 그리면 이렇습니다.
import seaborn as snsimport matplotlib.pyplot as plttips = sns.load_dataset("tips")sns.barplot(data=tips, x="day", y="tip")plt.title("Mean Tip by Day")plt.show()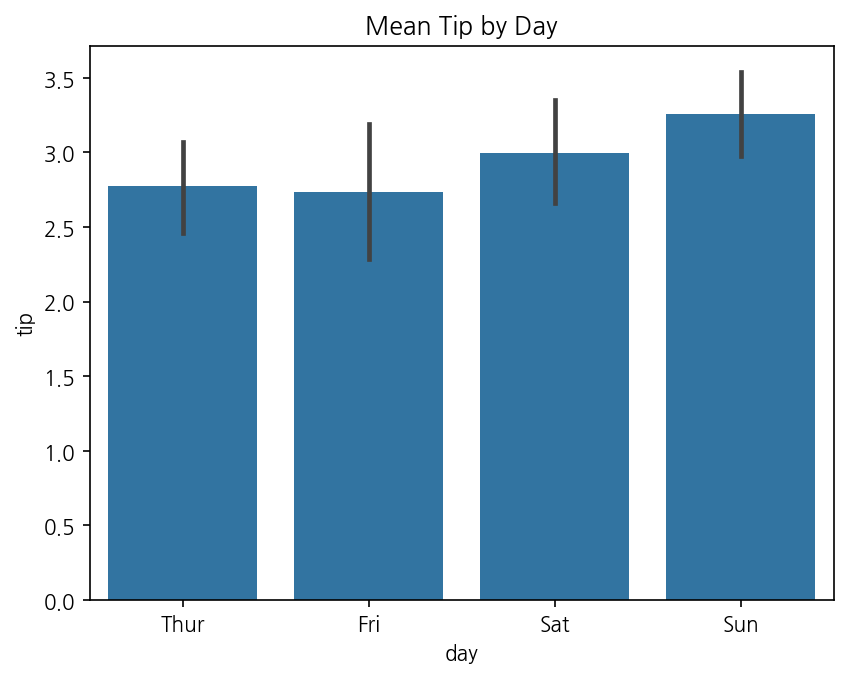
"아, 신뢰구간이 자동으로 나오네요."
민서가 결과 그래프를 보고 말했습니다. Seaborn의 barplot은 기본적으로 평균값을 막대로, 95% 신뢰구간을 오차막대로 함께 그립니다. 통계적으로 더 정직한 그래프가 두 줄로 완성됩니다.
히스토그램과 분포 곡선 비교
마지막으로 팁 분포를 히스토그램과 KDE(커널 밀도 추정) 곡선으로 함께 그려봤습니다.
Matplotlib으로 그리면 이렇습니다. 이 코드는 KDE 곡선을 직접 계산하기 위해 scipy가 필요합니다. 설치하지 않았다면 pip install scipy를 먼저 실행하세요.
import matplotlib.pyplot as pltimport numpy as npfrom scipy.stats import gaussian_kdeimport seaborn as snstips = sns.load_dataset("tips")fig, ax = plt.subplots(figsize=(8, 5))counts, bins, _ = ax.hist(tips["tip"], bins=20, density=True, alpha=0.5, color="steelblue")# KDE 직접 계산kde = gaussian_kde(tips["tip"])x = np.linspace(tips["tip"].min(), tips["tip"].max(), 200)ax.plot(x, kde(x), color="darkblue", linewidth=2)ax.set_xlabel("Tip")ax.set_ylabel("Density")ax.set_title("Tip Distribution")plt.show()
Seaborn으로 그리면 이렇습니다.
import seaborn as snsimport matplotlib.pyplot as plttips = sns.load_dataset("tips")sns.histplot(data=tips, x="tip", kde=True)plt.title("Tip Distribution")plt.show()
scipy까지 불러와서 KDE를 직접 계산하던 코드가 kde=True 하나로 줄었습니다.
"이제 납득이 가요."
민서가 고개를 끄덕였습니다.
핵심 차이점
두 라이브러리의 성격 차이를 정리하면 아래와 같습니다.
| 항목 | Matplotlib | Seaborn |
|---|---|---|
| 수준 | 저수준 (점, 선, 면 직접 제어) | 고수준 (통계 그래프 추상화) |
| 스타일 | 직접 지정 | 자동 스타일 + 테마 |
| 통계 계산 | 직접 계산 후 넘겨야 함 | 내장 (평균, CI, KDE 등) |
| DataFrame 지원 | 배열 추출 필요 | data=df, x="col" 직접 지정 |
| 범주형 그루핑 | 수동 분리 + 반복 호출 | hue, col, row 파라미터 |
| 커스터마이징 | 세밀하게 가능 | Matplotlib 레이어로 추가 가능 |
강주원 선배가 마무리했습니다.
"Matplotlib은 완전한 자유야. 원하는 걸 뭐든 만들 수 있어. 대신 다 직접 해야 해. Seaborn은 통계적 우아함이야. 흔히 쓰는 통계 그래프는 알아서 예쁘게 만들어줘. 발표 자료, 논문 그래프엔 Seaborn이 훨씬 빨라."
민서는 노트북을 열고 새 셀을 만들었습니다. 환경 설정부터 시작할 차례였습니다.