groupby와 시각화
"선배, groupby 결과를 바로 barplot에 넣으면 왜 에러가 나요?" 민서가 물었습니다.
선배가 설명합니다. "groupby 결과물은 Series야. Seaborn은 그 Series보다 원본 DataFrame을 더 좋아해. 방법을 알면 간단해."
groupby 결과 시각화하기
Seaborn의 barplot은 내부적으로 그룹별 집계를 자동으로 처리합니다. 그래서 원본 DataFrame을 그대로 넘기고, 어떤 열로 그룹을 나눌지만 알려주면 됩니다.
import seaborn as snsimport matplotlib.pyplot as pltimport pandas as pd# tips 데이터 로드tips = sns.load_dataset("tips")fig, axes = plt.subplots(1, 2, figsize=(12, 5))# 방법 1: Seaborn에게 그룹핑을 맡기기 (권장)# estimator 기본값이 'mean'이므로 요일별 평균 팁을 자동 계산sns.barplot(data=tips, x="day", y="tip", hue="sex", estimator="mean", errorbar="sd", ax=axes[0])axes[0].set_title("요일별 평균 팁 (Seaborn 자동 집계)")axes[0].set_xlabel("요일")axes[0].set_ylabel("평균 팁 ($)")# 방법 2: groupby로 직접 계산 후 reset_index()로 DataFrame 복원grouped = tips.groupby(["day", "sex"])["tip"].mean().reset_index()grouped.columns = ["day", "sex", "mean_tip"]sns.barplot(data=grouped, x="day", y="mean_tip", hue="sex", ax=axes[1])axes[1].set_title("요일별 평균 팁 (groupby 후 시각화)")axes[1].set_xlabel("요일")axes[1].set_ylabel("평균 팁 ($)")plt.tight_layout()plt.show()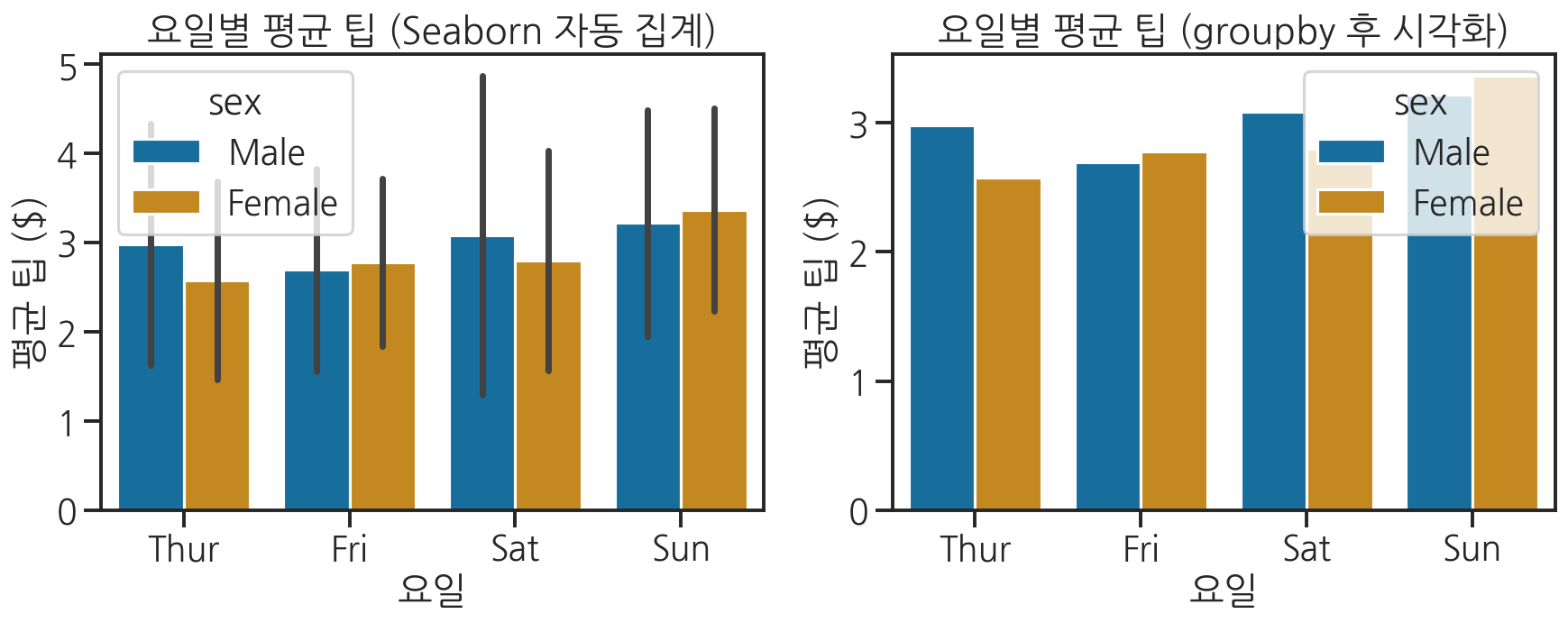
두 방법 모두 동일한 결과를 만듭니다. 방법 1은 코드가 짧고 오차 범위(errorbar)까지 자동으로 표시해줍니다. 방법 2는 중간 결과(grouped)를 직접 확인할 수 있어 디버깅에 유리합니다.
pivot_table + heatmap 조합
pivot_table은 행과 열의 교차 지점에 집계값을 배치합니다. 이 2차원 구조는 heatmap과 완벽하게 어울립니다.
import seaborn as snsimport matplotlib.pyplot as plttips = sns.load_dataset("tips")# pivot_table 생성: 행=요일, 열=시간대, 값=평균 팁pivot = tips.pivot_table( values="tip", index="day", columns="time", aggfunc="mean")print("pivot_table 결과:")print(pivot)# heatmap으로 시각화plt.figure(figsize=(6, 5))sns.heatmap( pivot, annot=True, # 각 셀에 값 표시 fmt=".2f", # 소수점 2자리 cmap="YlOrRd", # 노란색→주황색→빨간색 linewidths=0.5, # 셀 구분선 cbar_kws={"label": "평균 팁 ($)"})plt.title("요일 × 시간대별 평균 팁")plt.xlabel("시간대")plt.ylabel("요일")plt.tight_layout()plt.show()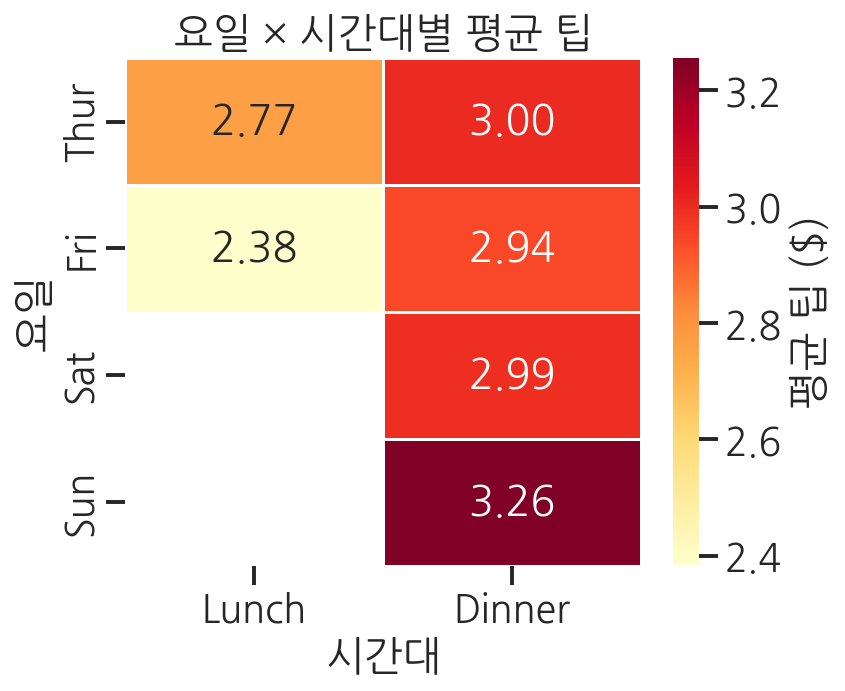
crosstab + heatmap으로 빈도 행렬 시각화
pd.crosstab()은 두 범주형 변수의 조합별 빈도를 세어줍니다. 설문 응답 분석이나 그룹 간 분포 비교에 자주 활용됩니다.
import seaborn as snsimport matplotlib.pyplot as pltimport pandas as pdtips = sns.load_dataset("tips")# crosstab: 요일별, 시간대별 방문 횟수crosstab = pd.crosstab(tips["day"], tips["time"])print("crosstab 결과 (빈도):")print(crosstab)# 비율로 변환 (행 기준 퍼센트)crosstab_pct = pd.crosstab(tips["day"], tips["time"], normalize="index") * 100fig, axes = plt.subplots(1, 2, figsize=(12, 4))# 절대 빈도 heatmapsns.heatmap(crosstab, annot=True, fmt="d", cmap="Blues", ax=axes[0])axes[0].set_title("요일별 방문 횟수 (절대값)")axes[0].set_xlabel("시간대")axes[0].set_ylabel("요일")# 비율 heatmapsns.heatmap(crosstab_pct, annot=True, fmt=".1f", cmap="Greens", ax=axes[1])axes[1].set_title("요일별 방문 비율 (%, 행 기준)")axes[1].set_xlabel("시간대")axes[1].set_ylabel("요일")plt.tight_layout()plt.show()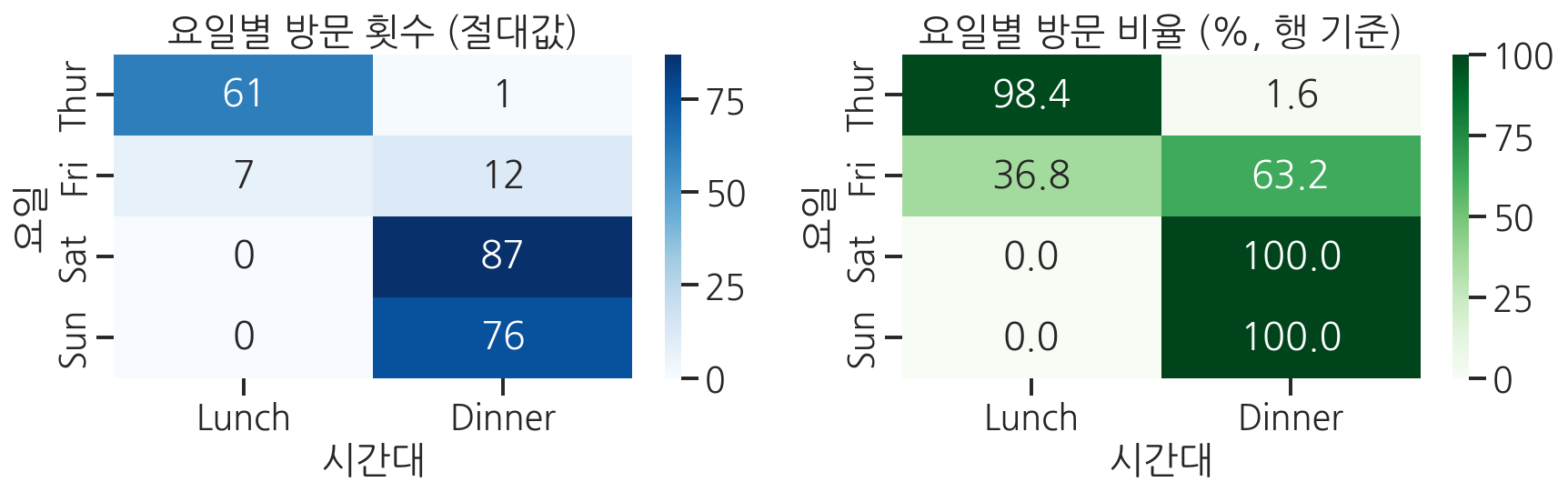
실전 워크플로우: 전처리 후 시각화
실제 데이터 분석에서는 시각화 전에 반드시 전처리가 필요합니다. 결측치나 잘못된 데이터 타입이 있으면 시각화 결과도 신뢰할 수 없기 때문입니다.
import seaborn as snsimport matplotlib.pyplot as pltimport pandas as pdimport numpy as np# 결측치와 이상치가 섞인 샘플 데이터 생성np.random.seed(42)n = 200raw_data = pd.DataFrame({ "category": np.random.choice(["A", "B", "C", "D"], size=n), "value": np.random.normal(50, 15, size=n), "region": np.random.choice(["서울", "경기", "부산", None], size=n, p=[0.4, 0.3, 0.2, 0.1])})# 결측치 일부 추가raw_data.loc[np.random.choice(n, 20, replace=False), "value"] = np.nanprint("=== 전처리 전 ===")print(f"전체 행 수: {len(raw_data)}")print(f"결측치 현황:\n{raw_data.isnull().sum()}")print(f"\ndtype:\n{raw_data.dtypes}")# ── 전처리 단계 ──────────────────────────────────────# 1. 결측치 제거clean_data = raw_data.dropna()# 2. 이상치 제거 (IQR 방법)Q1 = clean_data["value"].quantile(0.25)Q3 = clean_data["value"].quantile(0.75)IQR = Q3 - Q1clean_data = clean_data[ (clean_data["value"] >= Q1 - 1.5 * IQR) & (clean_data["value"] <= Q3 + 1.5 * IQR)]# 3. category를 Categorical 타입으로 변환 (순서 지정 가능)clean_data["category"] = pd.Categorical( clean_data["category"], categories=["A", "B", "C", "D"], ordered=True)print("\n=== 전처리 후 ===")print(f"전체 행 수: {len(clean_data)}")print(f"결측치 현황:\n{clean_data.isnull().sum()}")# ── 시각화 단계 ──────────────────────────────────────fig, axes = plt.subplots(1, 2, figsize=(12, 5))# 카테고리별 값 분포sns.boxplot(data=clean_data, x="category", y="value", hue="category", palette="Set2", legend=False, ax=axes[0])axes[0].set_title("카테고리별 값 분포 (전처리 후)")axes[0].set_xlabel("카테고리")axes[0].set_ylabel("값")# 지역별 카테고리 분포 (pivot_table + heatmap)pivot = clean_data.pivot_table( values="value", index="region", columns="category", aggfunc="mean")sns.heatmap(pivot, annot=True, fmt=".1f", cmap="coolwarm", center=50, ax=axes[1])axes[1].set_title("지역 × 카테고리별 평균값")axes[1].set_xlabel("카테고리")axes[1].set_ylabel("지역")plt.tight_layout()plt.show()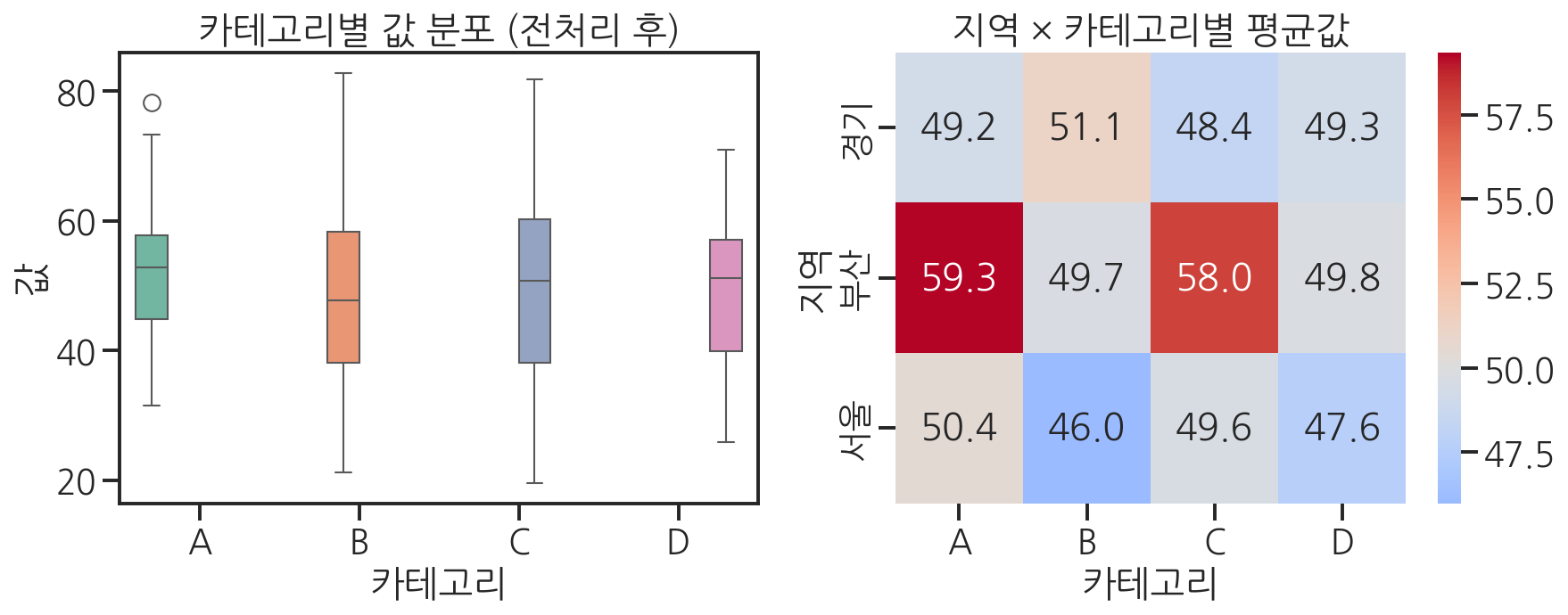
선배가 강조합니다. "시각화 코드보다 전처리 코드가 더 길 때도 많아. 그게 정상이야. 데이터를 믿을 수 있어야 그래프도 믿을 수 있거든."
핵심 정리
- Seaborn의
barplot은 원본 DataFrame을 넣고x,y,hue로 그룹을 지정하면 집계를 자동으로 처리합니다. pivot_table(values, index, columns, aggfunc)으로 2차원 집계 테이블을 만들고heatmap으로 시각화합니다.pd.crosstab()은 두 범주형 변수의 빈도 행렬을 만들어 heatmap과 잘 어울립니다.- 실전에서는 결측치 제거, 이상치 처리, 타입 변환 등 전처리를 먼저 마친 후 시각화를 시작합니다.