히스토그램 (histplot)
민서가 팁 금액이 얼마씩 주로 주어지는지 궁금해졌습니다. 평균 말고, 실제로 어느 금액대에 가장 많이 몰려 있는지가 알고 싶었습니다.
"히스토그램 써봐. 데이터를 구간별로 나눠서 각 구간에 몇 개가 있는지 막대로 보여줘."
이 차트가 보여주는 것
히스토그램은 연속 변수의 전체 범위를 일정 간격(bin)으로 나누고, 각 구간에 데이터가 몇 개 들어있는지 막대 높이로 표현합니다. 막대가 높은 구간에 데이터가 많이 몰려 있습니다.
import seaborn as snsimport matplotlib.pyplot as plttips = sns.load_dataset("tips")sns.histplot(data=tips, x="total_bill", bins=20)plt.title("계산 금액 분포")plt.xlabel("계산 금액 (달러)")plt.ylabel("빈도")plt.show()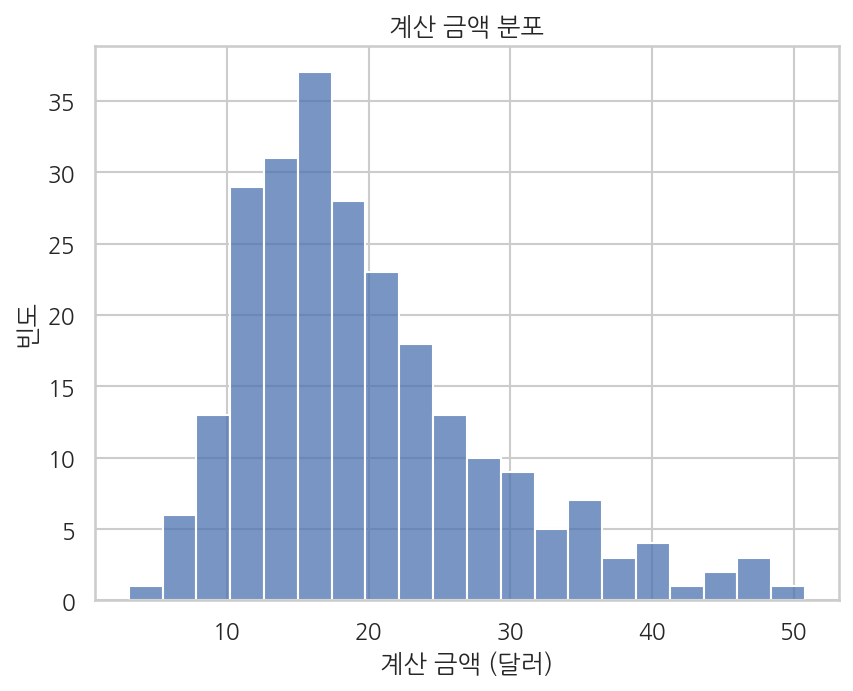
bins: 구간 수가 모양을 바꾼다
bins 수에 따라 히스토그램의 모양이 크게 달라집니다.
import seaborn as snsimport matplotlib.pyplot as plttips = sns.load_dataset("tips")fig, axes = plt.subplots(1, 3, figsize=(15, 4))for ax, bins in zip(axes, [5, 20, 50]): sns.histplot(data=tips, x="total_bill", bins=bins, ax=ax) ax.set_title(f"bins={bins}") ax.set_xlabel("계산 금액 (달러)")plt.suptitle("bins 수에 따른 히스토그램 모양 변화", y=1.02)plt.tight_layout()plt.show()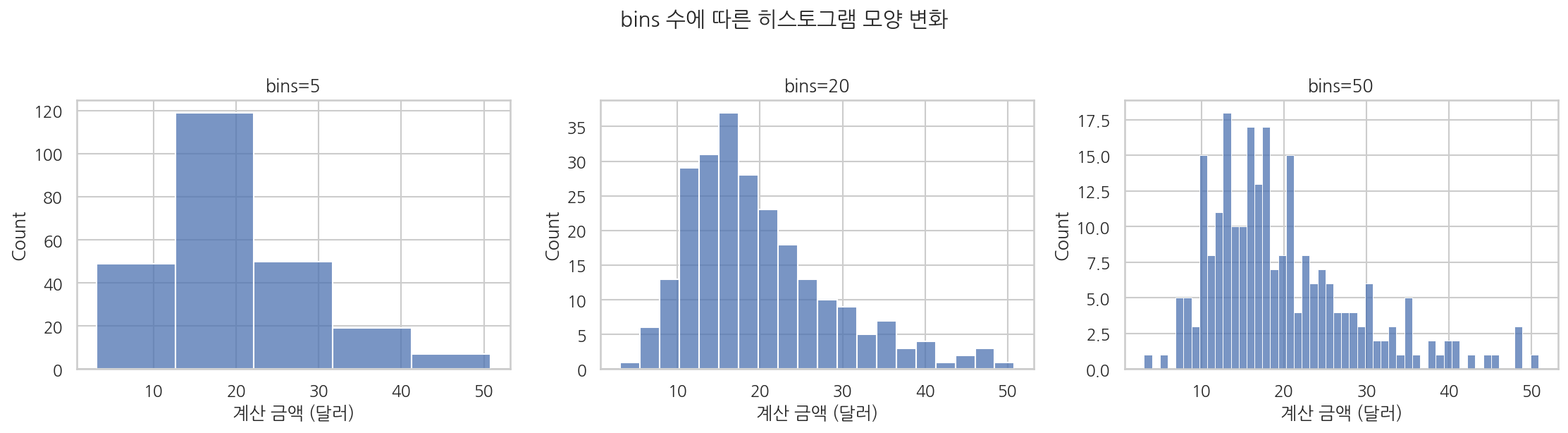
bins가 너무 적으면 데이터의 세부 모양을 잃고, 너무 많으면 노이즈가 두드러집니다. 데이터의 특성에 맞게 조절합니다.
kde=True: 밀도 곡선 오버레이
kde=True를 추가하면 히스토그램 위에 KDE 곡선이 함께 그려집니다. 분포의 전체적인 형태를 더 부드럽게 파악할 수 있습니다.
import seaborn as snsimport matplotlib.pyplot as plttips = sns.load_dataset("tips")sns.histplot(data=tips, x="total_bill", bins=20, kde=True)plt.title("계산 금액 분포 (KDE 포함)")plt.xlabel("계산 금액 (달러)")plt.show()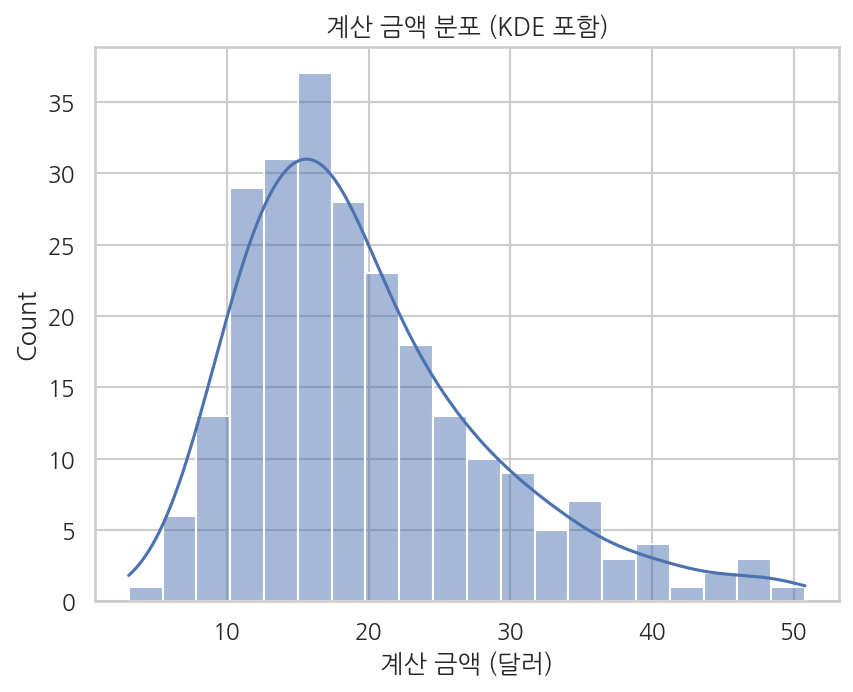
hue로 그룹별 비교
import seaborn as snsimport matplotlib.pyplot as plttips = sns.load_dataset("tips")fig, axes = plt.subplots(1, 3, figsize=(15, 4))# layer (기본): 겹쳐서 표시sns.histplot(data=tips, x="total_bill", hue="time", multiple="layer", alpha=0.5, ax=axes[0])axes[0].set_title("multiple='layer' (겹쳐서)")# dodge: 나란히 표시sns.histplot(data=tips, x="total_bill", hue="time", multiple="dodge", ax=axes[1])axes[1].set_title("multiple='dodge' (나란히)")# stack: 쌓아서 표시sns.histplot(data=tips, x="total_bill", hue="time", multiple="stack", ax=axes[2])axes[2].set_title("multiple='stack' (쌓아서)")plt.suptitle("multiple 옵션 비교 (점심 vs 저녁)", y=1.02)plt.tight_layout()plt.show()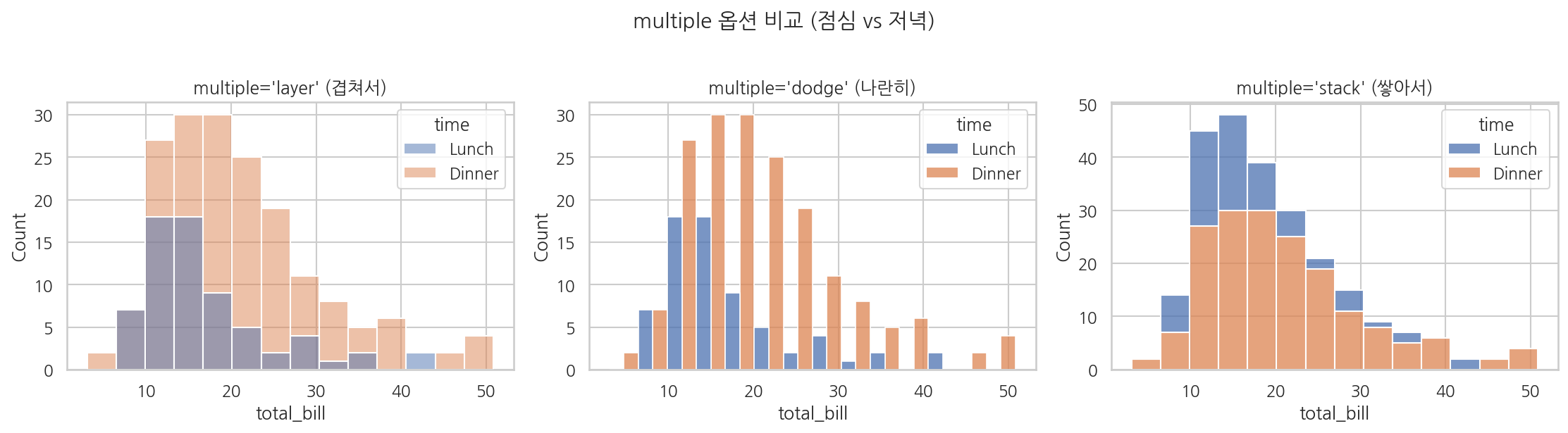
자주 쓰는 파라미터 정리
| 파라미터 | 역할 | 예시 |
|---|---|---|
x |
분포를 볼 변수 | x="total_bill" |
bins |
구간 수 | bins=20 |
kde |
밀도 곡선 오버레이 | kde=True |
hue |
그룹 구분 | hue="time" |
multiple |
그룹 표시 방식 | "layer", "dodge", "stack" |
stat |
y축 통계량 | stat="density", stat="probability" |
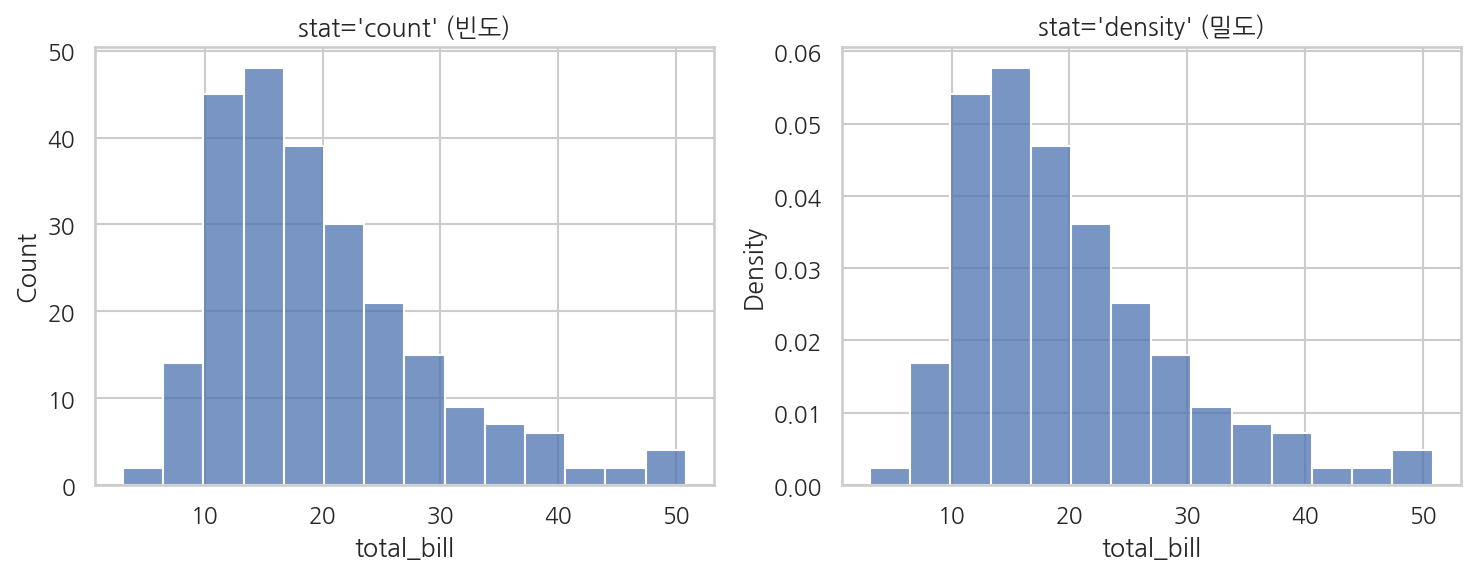
stat 파라미터: y축이 의미하는 것을 바꾼다
기본값 stat="count"는 각 bin에 몇 개의 데이터가 있는지 보여줍니다. stat="density"로 바꾸면 y축이 밀도가 되어 다른 크기의 데이터셋과 비교하기 편합니다.
import seaborn as snsimport matplotlib.pyplot as plttips = sns.load_dataset("tips")fig, axes = plt.subplots(1, 2, figsize=(10, 4))sns.histplot(data=tips, x="total_bill", stat="count", ax=axes[0])axes[0].set_title("stat='count' (빈도)")sns.histplot(data=tips, x="total_bill", stat="density", ax=axes[1])axes[1].set_title("stat='density' (밀도)")plt.tight_layout()plt.show()