클러스터맵 (clustermap)
히트맵을 보던 민서가 아쉬움을 느꼈습니다.
"변수들이 알파벳 순서로 정렬돼 있는데, 비슷한 것끼리 모아서 보면 더 좋을 것 같아요."
강주원 선배가 말했습니다.
"clustermap이 정확히 그걸 해줘. 비슷한 패턴을 가진 행이나 열을 자동으로 묶어서 가까운 위치에 배치해줘."
이 차트가 보여주는 것
clustermap은 히트맵에 계층적 군집 분석(hierarchical clustering)을 결합한 차트입니다. 비슷한 값 패턴을 가진 행(또는 열)을 자동으로 묶어 재배열하고, 묶인 과정을 덴드로그램(수형도)으로 표시합니다.
"비슷한 패턴을 가진 행/열을 자동으로 묶어준다." 이것이 핵심입니다.
기본 clustermap
import seaborn as snsimport matplotlib.pyplot as pltflights = sns.load_dataset("flights")# 피벗 테이블로 월x연도 행렬 만들기flights_pivot = flights.pivot(index="month", columns="year", values="passengers")sns.clustermap(flights_pivot, cmap="Blues", figsize=(10, 8))plt.suptitle("항공 승객 수 클러스터맵", y=1.02)plt.show()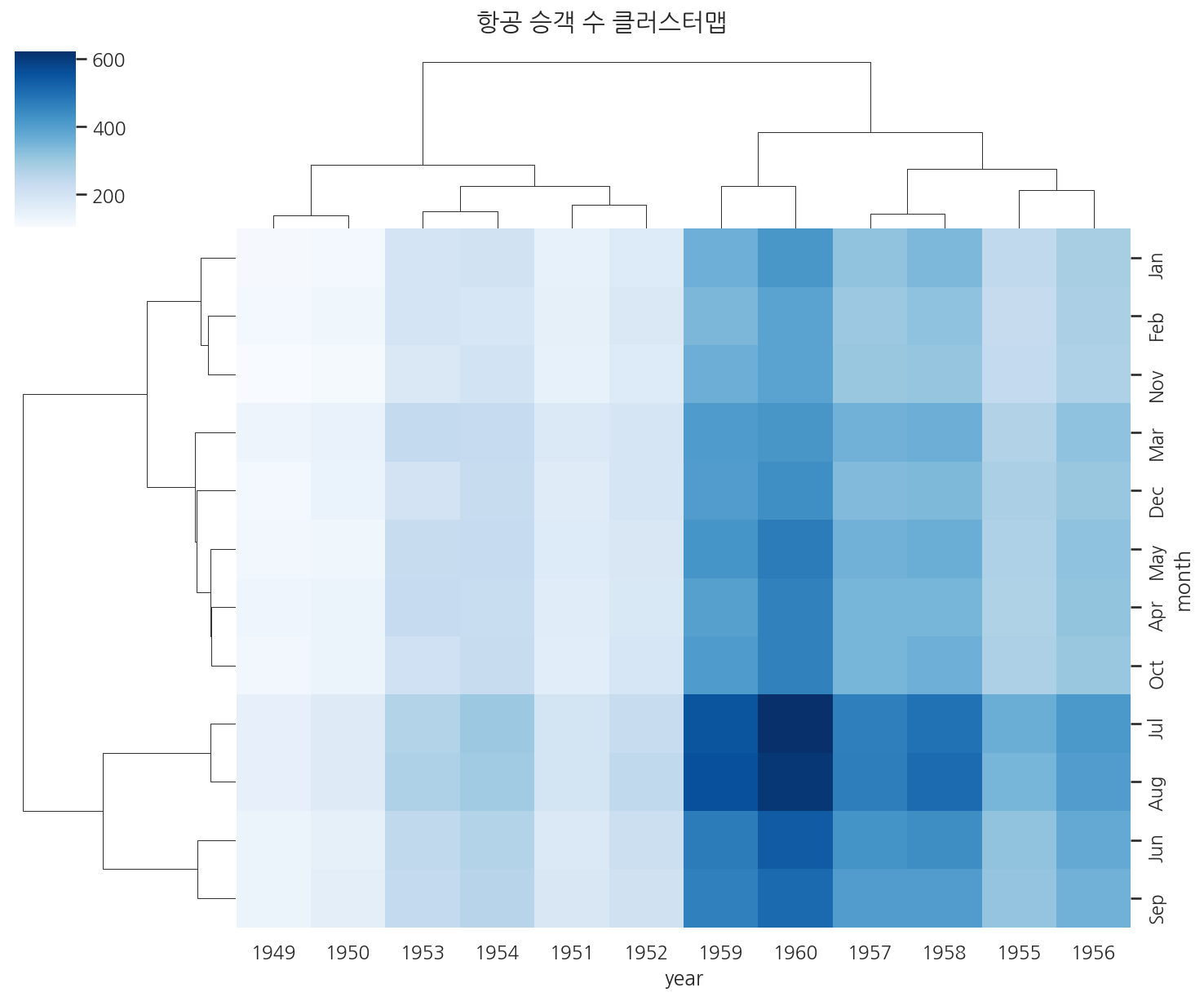
원래 순서대로라면 1월~12월, 1949~1960년이지만, clustermap은 비슷한 패턴을 가진 달과 연도를 묶어 재배열합니다.
standard_scale: 정규화
값의 스케일이 다를 때는 정규화가 필요합니다. standard_scale=1은 각 열을 0~1 범위로 정규화하고, standard_scale=0은 각 행을 정규화합니다.
import seaborn as snsimport matplotlib.pyplot as pltflights = sns.load_dataset("flights")flights_pivot = flights.pivot(index="month", columns="year", values="passengers")fig, axes_list = plt.subplots(1, 1, figsize=(10, 8))g = sns.clustermap( flights_pivot, standard_scale=1, # 열 기준 정규화 (연도별 상대적 크기 비교) cmap="Blues", figsize=(10, 8), annot=False)plt.suptitle("열 정규화 클러스터맵", y=1.02)plt.show()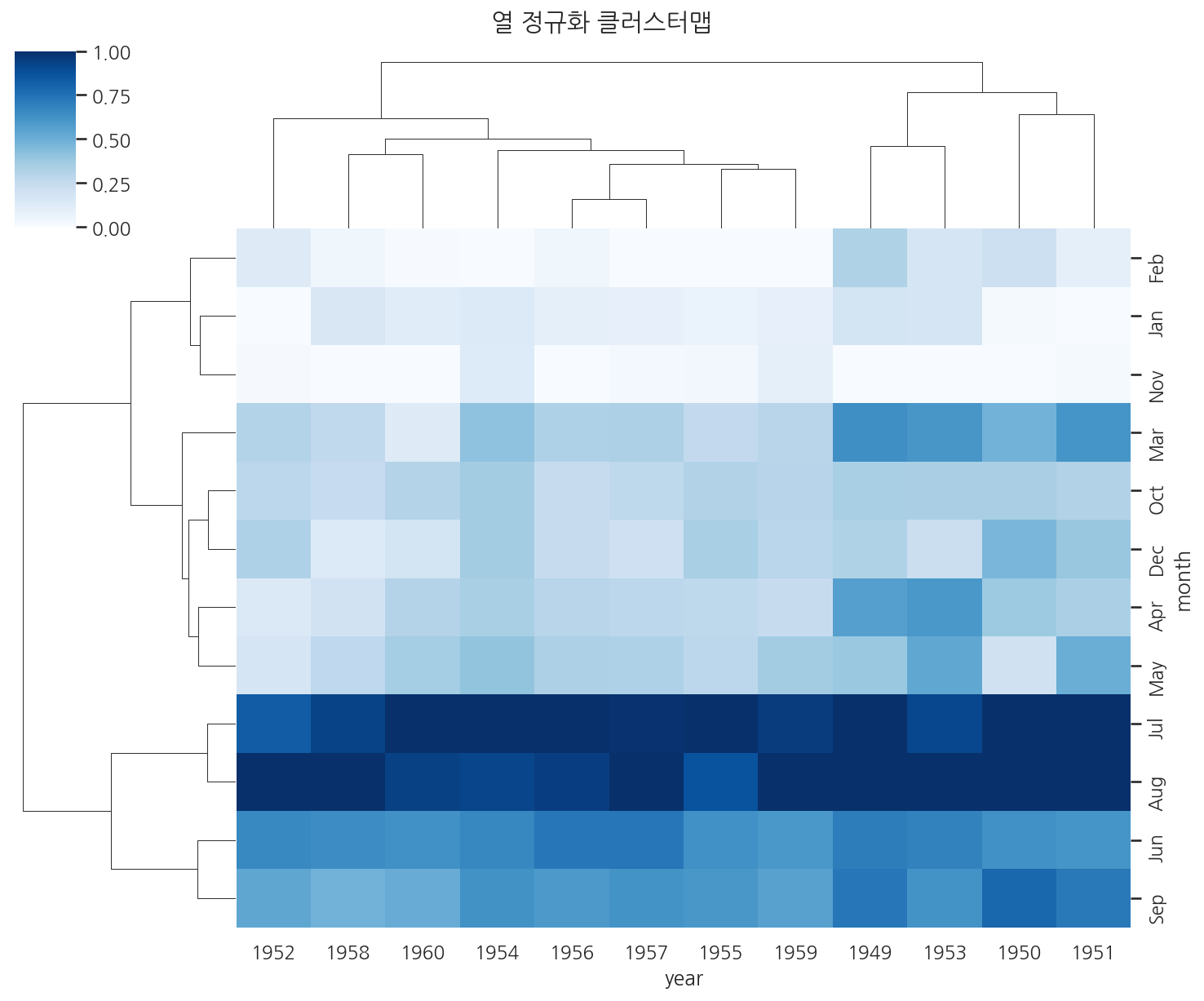
정규화를 하면 연도마다 절대적인 승객 수가 달라도, 월별 패턴(여름에 많고 겨울에 적음)이 더 잘 드러납니다.
덴드로그램 해석
clustermap의 위쪽과 왼쪽에 수형도(dendrogram)가 그려집니다. 수형도에서 두 가지를 읽습니다.
첫째, 같은 가지(branch)에 묶인 것들은 서로 비슷한 패턴을 가집니다. 둘째, 두 묶음이 연결되는 위치가 높을수록 두 묶음의 차이가 크다는 뜻입니다.
method와 metric 파라미터
군집화 방법과 거리 측정 방식을 바꿀 수 있습니다.
import seaborn as snsimport matplotlib.pyplot as pltflights = sns.load_dataset("flights")flights_pivot = flights.pivot(index="month", columns="year", values="passengers")# method: 군집 병합 방식# 'average' (기본), 'complete', 'single', 'ward'# metric: 거리 측정 방식# 'euclidean' (기본), 'correlation', 'cosine'g = sns.clustermap( flights_pivot, method="ward", # Ward 연결법: 군집 내 분산을 최소화 metric="euclidean", standard_scale=1, cmap="coolwarm", figsize=(10, 8))plt.suptitle("Ward 연결법 클러스터맵", y=1.02)plt.show()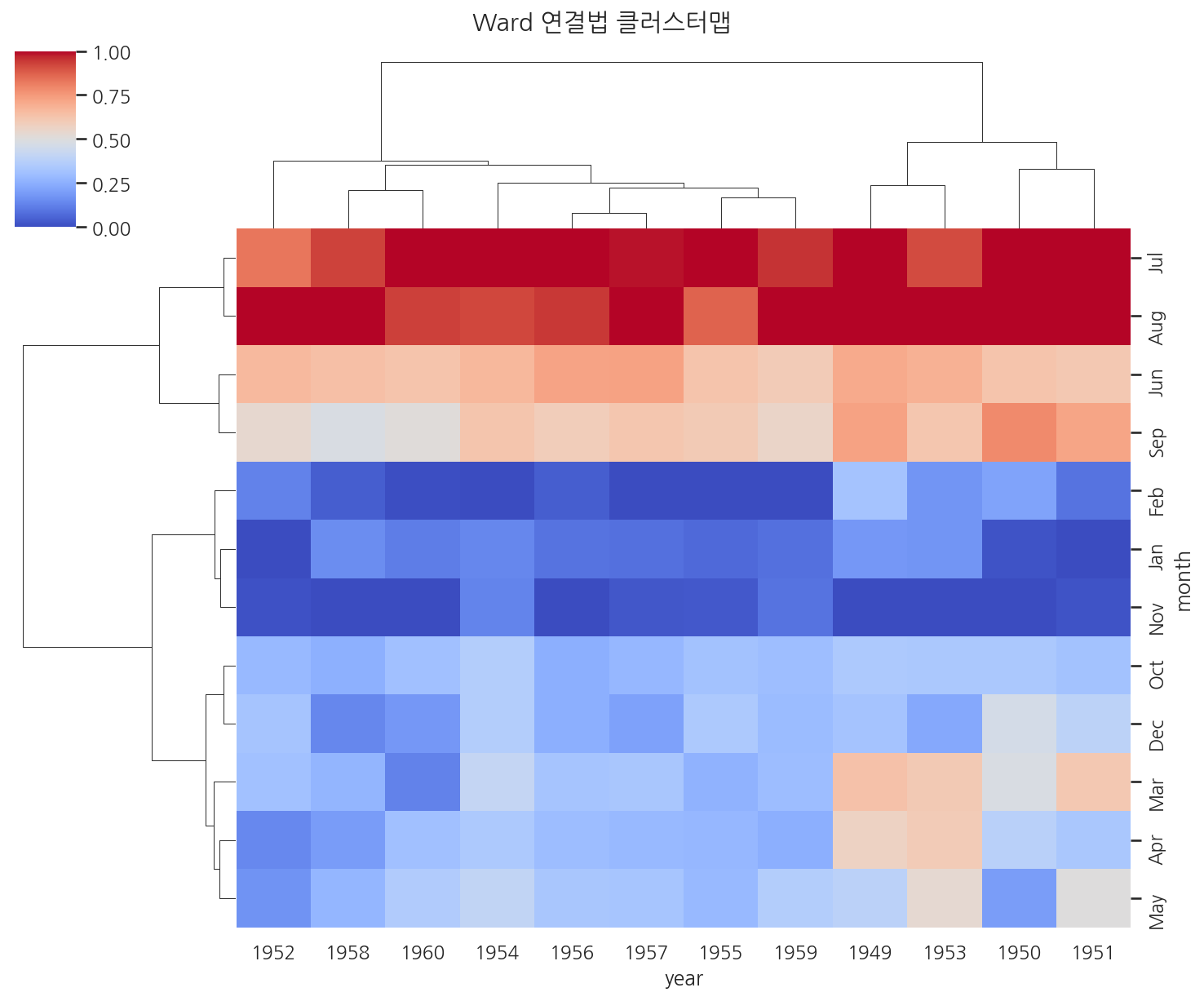
상관계수 기반의 유사성을 쓰고 싶다면 metric="correlation"이 적합합니다.
col_cluster, row_cluster: 군집화 방향 선택
행 또는 열 중 하나만 군집화할 수도 있습니다.
import seaborn as snsimport matplotlib.pyplot as pltflights = sns.load_dataset("flights")flights_pivot = flights.pivot(index="month", columns="year", values="passengers")g = sns.clustermap( flights_pivot, col_cluster=False, # 열(연도)은 원래 순서 유지 row_cluster=True, # 행(월)만 군집화 cmap="Blues", standard_scale=1, figsize=(10, 8))plt.suptitle("행만 군집화 (열은 연도 순서 유지)", y=1.02)plt.show()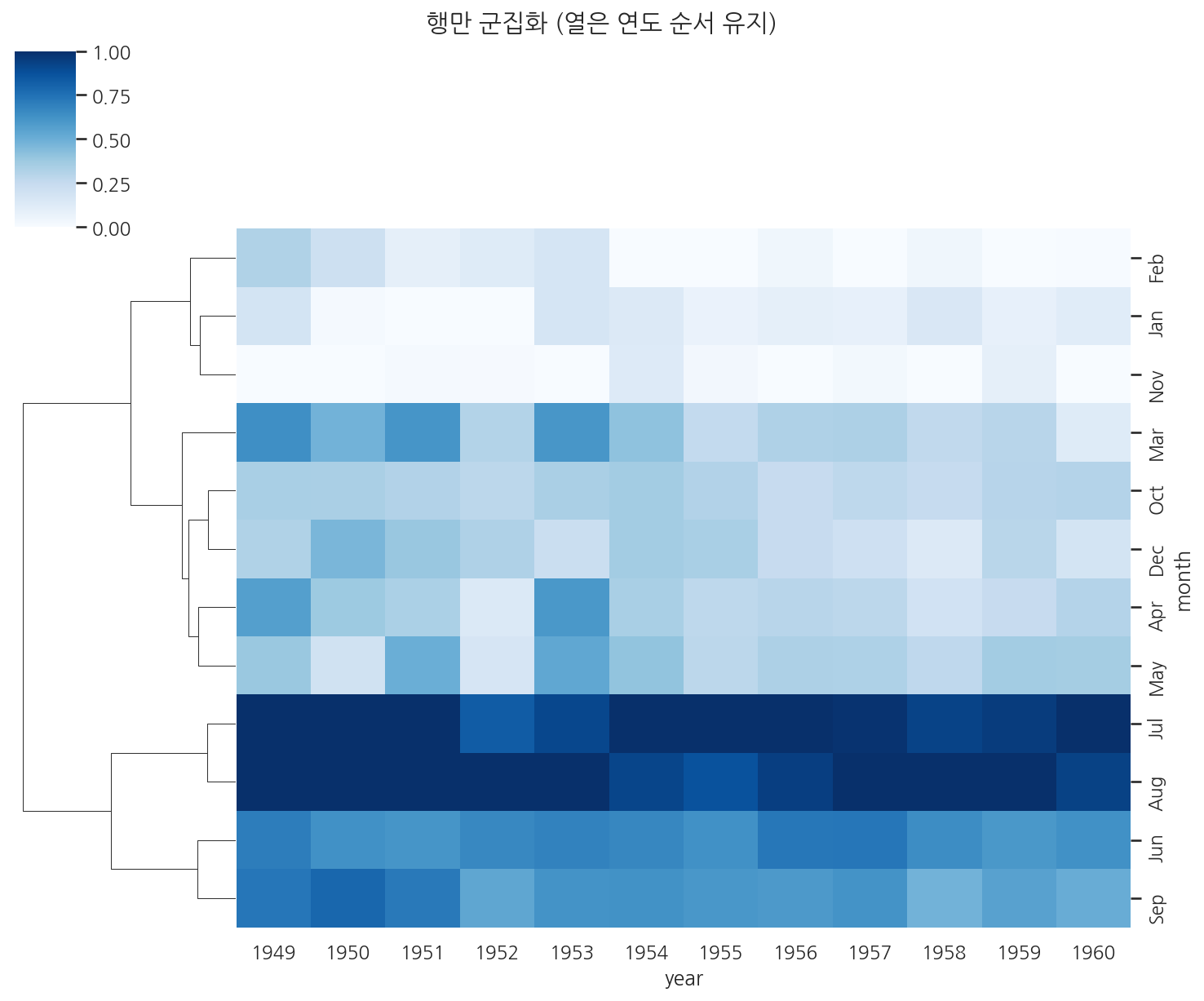
연도 순서를 유지하면서 비슷한 패턴의 달만 묶어볼 때 유용합니다.