DataFrame 직접 연동
"Seaborn 함수 쓸 때 매번 df['열이름'] 이렇게 꺼내야 해요?" 민서가 물었습니다.
선배가 고개를 저었습니다. "아니야. data=df 하고 x='열이름' 하면 끝이야. Seaborn이 알아서 꺼내줘."
data 파라미터의 힘
Seaborn의 모든 함수는 data 파라미터에 Pandas DataFrame을 받습니다. 그리고 x, y, hue 같은 파라미터에는 열 이름을 문자열로 전달하면 됩니다.
import seaborn as snsimport matplotlib.pyplot as pltimport pandas as pd# 샘플 데이터df = sns.load_dataset("tips")# 열 이름만 문자열로 전달하면 끝sns.scatterplot(data=df, x="total_bill", y="tip", hue="sex")plt.title("청구 금액과 팁의 관계")plt.show()
이 방식의 장점은 단순히 편리함만이 아닙니다. Seaborn이 DataFrame의 열 이름을 축 레이블로 자동으로 사용하기 때문에, 별도로 xlabel, ylabel을 설정하지 않아도 의미 있는 레이블이 붙습니다.
tidy data란 무엇인가
Seaborn은 tidy data(정돈된 데이터) 형태를 선호합니다. tidy data의 규칙은 간단합니다.
- 한 행은 하나의 관측값을 나타냅니다.
- 한 열은 하나의 변수를 나타냅니다.
- 하나의 표는 하나의 관측 단위를 나타냅니다.
예를 들어 학생별 과목 점수를 기록할 때, wide-form과 long-form(tidy) 두 가지 방식이 있습니다.
wide-form (비선호):
| 학생 | 수학 | 영어 | 과학 |
|---|---|---|---|
| 민서 | 85 | 92 | 78 |
| 지호 | 90 | 88 | 95 |
long-form / tidy data (선호):
| 학생 | 과목 | 점수 |
|---|---|---|
| 민서 | 수학 | 85 |
| 민서 | 영어 | 92 |
| 민서 | 과학 | 78 |
| 지호 | 수학 | 90 |
| ... | ... | ... |
Seaborn에서 hue, col, row 같은 그룹핑 기능을 쓰려면 long-form이 훨씬 자연스럽습니다. wide-form에서는 "어떤 열이 어떤 변수인지" Seaborn이 파악하기 어렵기 때문입니다.
pd.melt()로 wide → long 변환
현실에서 데이터는 종종 wide-form으로 주어집니다. 엑셀에서 만든 표나 보고서 형식의 데이터가 대표적입니다. 이럴 때 pd.melt()를 사용해 long-form으로 변환합니다.
import pandas as pd# wide-form 데이터wide_df = pd.DataFrame({ "학생": ["민서", "지호", "수연"], "수학": [85, 90, 88], "영어": [92, 88, 95], "과학": [78, 95, 82]})print("wide-form:")print(wide_df)# pd.melt()로 long-form으로 변환# id_vars: 그대로 유지할 열# var_name: 기존 열 이름들이 들어갈 새 열의 이름# value_name: 값들이 들어갈 새 열의 이름long_df = pd.melt( wide_df, id_vars=["학생"], var_name="과목", value_name="점수")print("\nlong-form (tidy):")print(long_df)iris 데이터로 변환 실습
실제로 wide-form 데이터를 long-form으로 변환하고 시각화해보겠습니다. iris 데이터셋은 꽃잎과 꽃받침의 길이/너비가 각각 별도 열로 구성된 wide-form입니다.
import seaborn as snsimport matplotlib.pyplot as pltimport pandas as pd# iris 데이터 로드iris = sns.load_dataset("iris")print("원본 iris 데이터 (wide-form):")print(iris.head())print(f"\n크기: {iris.shape}")# wide → long 변환# species 열은 그대로 유지하고, 나머지 수치 열들을 녹임iris_long = pd.melt( iris, id_vars=["species"], var_name="measurement", value_name="value")print("\n변환 후 (long-form):")print(iris_long.head(8))print(f"크기: {iris_long.shape}")# wide-form으로는 하나의 boxplot에 4가지 측정값을 한번에 비교하기 어려움# long-form이면 x='measurement', y='value', hue='species'로 바로 시각화 가능fig, axes = plt.subplots(1, 2, figsize=(14, 5))# wide-form: 하나의 변수만 시각화 가능sns.boxplot(data=iris, x="species", y="sepal_length", ax=axes[0])axes[0].set_title("wide-form: 꽃받침 길이만 비교")axes[0].set_xlabel("품종")axes[0].set_ylabel("길이 (cm)")# long-form: 모든 측정값을 한번에 비교sns.boxplot(data=iris_long, x="measurement", y="value", hue="species", ax=axes[1])axes[1].set_title("long-form: 모든 측정값 비교")axes[1].set_xlabel("측정 항목")axes[1].set_ylabel("값 (cm)")axes[1].tick_params(axis='x', rotation=15)axes[1].legend(title="품종", bbox_to_anchor=(1.05, 1), loc='upper left')plt.tight_layout()plt.show()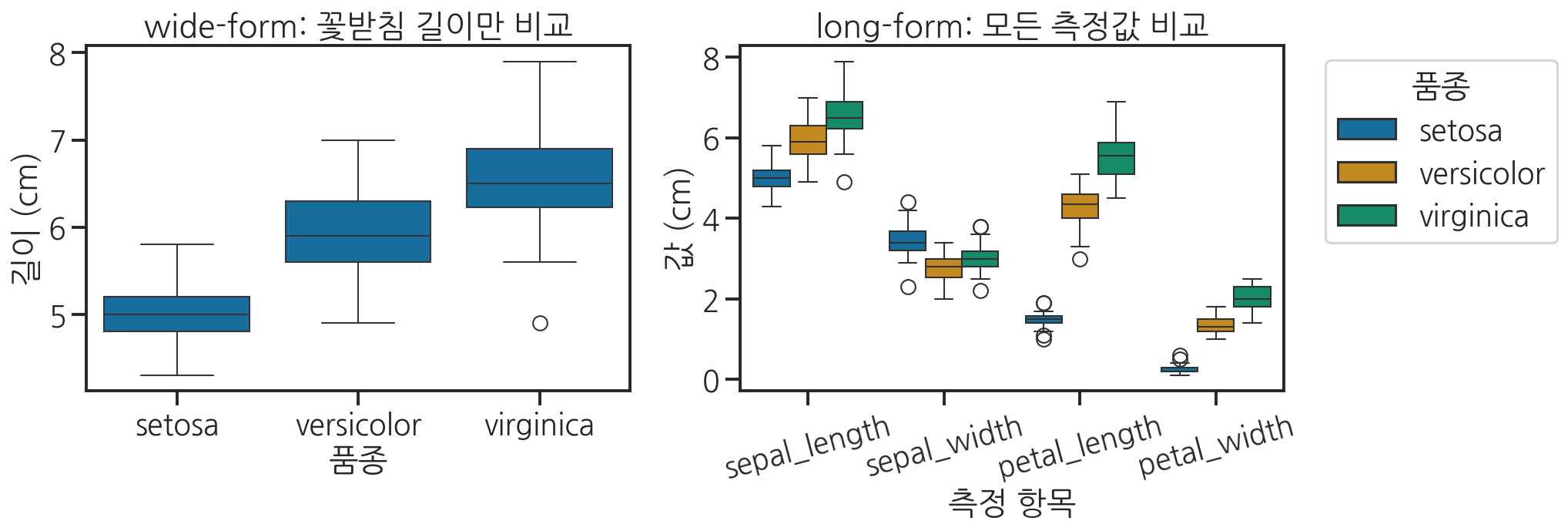
오른쪽 차트를 보면, long-form으로 변환한 덕분에 4가지 측정값을 3가지 품종과 함께 한 번에 비교할 수 있습니다. wide-form으로는 이런 시각화를 만들기 위해 훨씬 복잡한 코드가 필요했을 것입니다.
핵심 정리
- Seaborn 함수의
data파라미터에 DataFrame을 넣고,x,y,hue에 열 이름(문자열)을 전달합니다. - tidy data는 "한 행 = 한 관측, 한 열 = 한 변수" 원칙을 따릅니다.
- wide-form 데이터는
pd.melt(id_vars, var_name, value_name)으로 long-form으로 변환합니다. - long-form 데이터는 Seaborn의
hue,col,row기능을 최대한 활용할 수 있게 해줍니다.